Azure Function上でSpring BatchのChunkモデルを利用してDBデータをCSVに出力してみた
これまでこのブログでは、Blob上のCSVファイルをDBのテーブルに書き込む処理を作成していたが、逆に、DBのテーブルデータをBlob上のCSVファイルに出力することもできる。
今回は、Azure Function上でSpring BatchのChunkモデルを利用して、DBのテーブルデータをBlob上のCSVファイルに出力してみたので、そのサンプルプログラムを共有する。
前提条件
下記記事のサンプルプログラムを作成済であること。

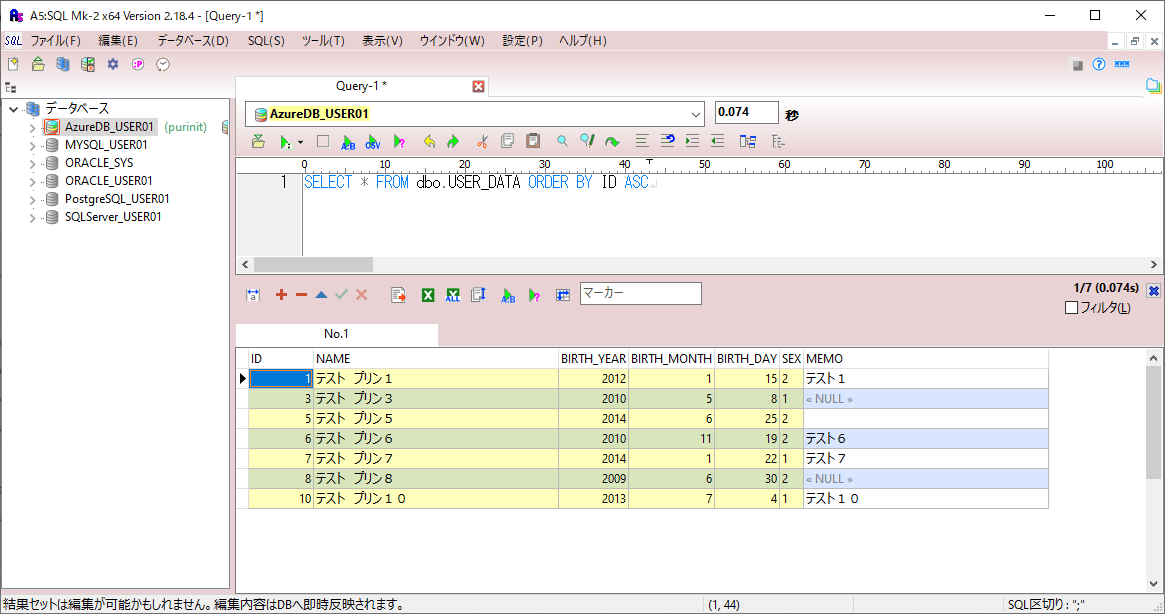
また、取得元のDB(Azure SQL Database上のUSER_DATAテーブル)に、以下のデータが設定済であること。
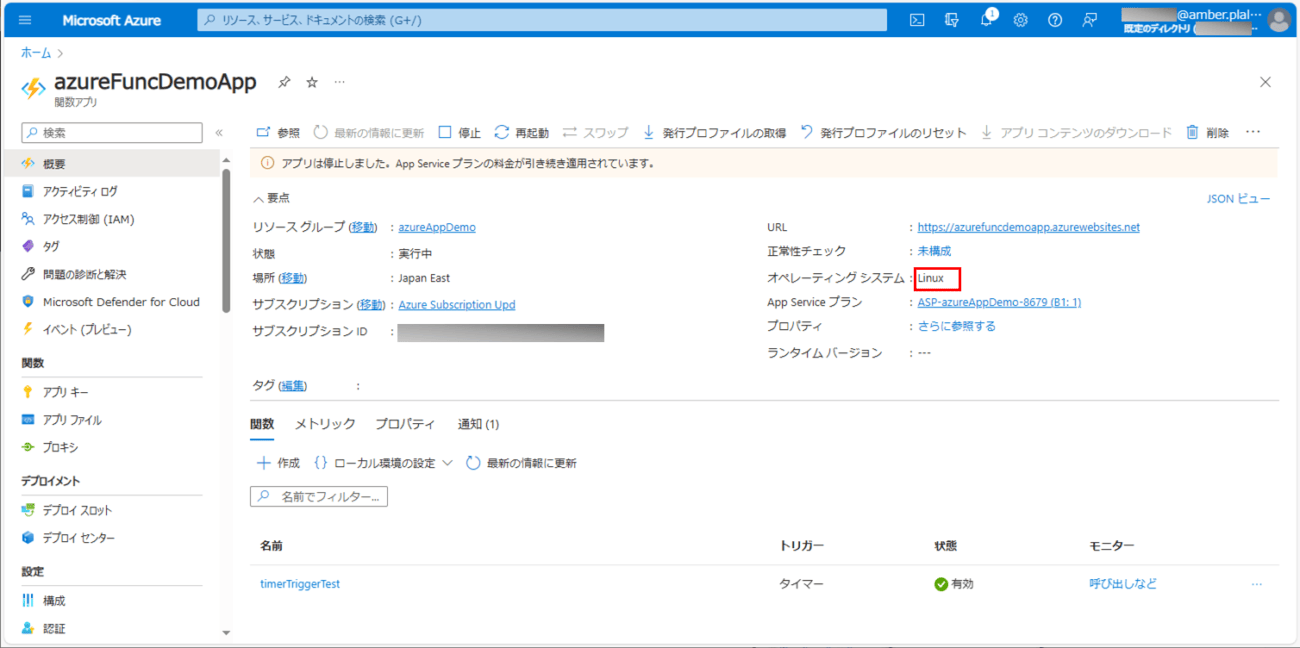
さらに、Azure Functionsのオペレーティングシステムが、以下の赤枠のように、Linuxであること。
サンプルプログラムの作成
作成したサンプルプログラムの構成は、以下の通り。
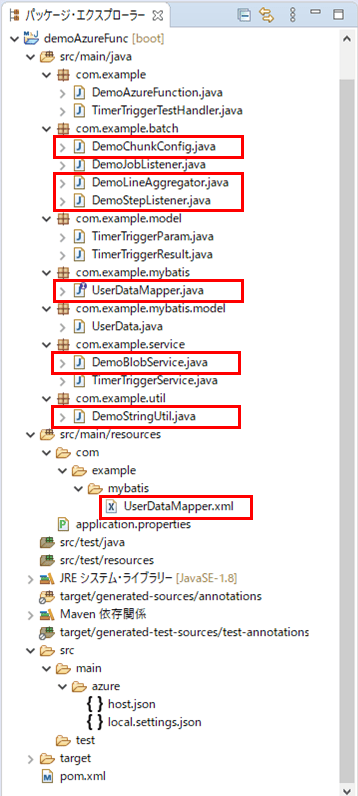
なお、上記の赤枠は、今回追加・変更したプログラムである。
Spring Batchの定義クラスは以下の通りで、DBのデータをCSVファイルに出力する処理と、DemoStepListenerの呼出処理を追加している。なお、CSVファイルは、Azure Functions(Linux)上の、「/home/tmp_user_data.csv」に出力するようにしている。
package com.example.batch;
import java.io.IOException;
import java.io.Writer;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.batch.MyBatisPagingItemReader;
import org.mybatis.spring.batch.builder.MyBatisPagingItemReaderBuilder;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.file.FlatFileHeaderCallback;
import org.springframework.batch.item.file.FlatFileItemWriter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.FileSystemResource;
import com.example.mybatis.model.UserData;
import lombok.RequiredArgsConstructor;
@Configuration
@EnableBatchProcessing
@RequiredArgsConstructor
public class DemoChunkConfig {
/** ジョブ生成ファクトリ */
public final JobBuilderFactory jobBuilderFactory;
/** ステップ生成ファクトリ */
public final StepBuilderFactory stepBuilderFactory;
/** SQLセッションファクトリ */
public final SqlSessionFactory sqlSessionFactory;
/** ステップの前後処理 */
private final DemoStepListener demoStepListener;
/** 取得したUSER_DATAテーブルのデータを出力するファイルパス */
private static final String TMP_FILE_PATH = "/home/";
/** 取得したUSER_DATAテーブルのデータを出力するファイル名 */
private static final String TMP_FILE_NAME = "tmp_user_data.csv";
/** 改行コード */
private static final String LINE_SEPARATOR = "\r\n";
/** 文字コード */
private static final String CHARCTER_CODE = "UTF-8";
/** チャンクサイズ */
private final int CHUNK_SIZE = 3;
/**
* MyBatisPagingItemReaderを使ってUSER_DATAデータをページを分けて取得する.
* @return 読み込みオブジェクト
*/
@Bean
public MyBatisPagingItemReader<UserData> reader(){
return new MyBatisPagingItemReaderBuilder<UserData>()
.sqlSessionFactory(sqlSessionFactory)
.queryId("com.example.mybatis.UserDataMapper.findAll")
.pageSize(CHUNK_SIZE)
.build();
}
/**
* 読み込んだDBのデータを、ローカルのファイルに書き込む.
* @return 書き込みオブジェクト
*/
@Bean
public FlatFileItemWriter<UserData> writer(){
FlatFileItemWriter<UserData> writer = new FlatFileItemWriter<UserData>();
// ファイルの出力先を指定
writer.setResource(new FileSystemResource(TMP_FILE_PATH + TMP_FILE_NAME));
// ファイルを書き込む際の文字コード・改行コードを指定
writer.setEncoding(CHARCTER_CODE);
writer.setLineSeparator(LINE_SEPARATOR);
// ファイルを追記書き込みNGとする
writer.setAppendAllowed(false);
// ファイルに書き込む
// ヘッダー行を定義する
writer.setHeaderCallback(new FlatFileHeaderCallback() {
public void writeHeader(Writer ioWriter) throws IOException {
ioWriter.append("id,name,birth_year,birth_month,birth_day,sex,memo");
}
});
// 書き込む文字列は、DemoLineAggregatorクラスで設定
writer.setLineAggregator(new DemoLineAggregator());
return writer;
}
/**
* Spring Batchのジョブ内で指定する処理単位(ステップ)を定義する.
* @param reader 読み込みオブジェクト
* @param writer 書き込みオブジェクト
* @return Spring Batchのジョブ内で指定する処理単位
*/
@Bean
public Step step(MyBatisPagingItemReader<UserData> reader
, ItemWriter<UserData> writer) {
// 生成するステップ内で読み込み/書き込みを一連の流れを指定する
// その際、読み込みデータの加工は行わず、
// チャンクサイズ(=何件読み込む毎にコミットするか)を指定している
return stepBuilderFactory.get("step")
.<UserData, UserData>chunk(CHUNK_SIZE)
.reader(reader)
.writer(writer)
.listener(demoStepListener)
.build();
}
/**
* Spring Batchのジョブを定義する.
* @param jobListener 実行前後の処理(リスナ)
* @param step 実行するステップ
* @return Spring Batchのジョブ
*/
@Bean
public Job updateUserData(DemoJobListener jobListener, Step step) {
// 生成するジョブ内で、実行前後の処理(リスナ)と処理単位(ステップ)を指定する
return jobBuilderFactory
.get("selectUserData")
.incrementer(new RunIdIncrementer())
.listener(jobListener)
.flow(step)
.end()
.build();
}
}また、CSVファイルに書き込むデータ内容を定義したクラスの内容は、以下の通り。
package com.example.batch;
import org.springframework.batch.item.file.transform.LineAggregator;
import com.example.mybatis.model.UserData;
import com.example.util.DemoStringUtil;
public class DemoLineAggregator implements LineAggregator<UserData>{
/**
* 書き込みデータ(1行分)の設定内容を指定する.
*/
@Override
public String aggregate(UserData userData) {
StringBuilder sb = new StringBuilder();
// ID
sb.append(userData.getId());
sb.append(",");
// 名前
sb.append(DemoStringUtil.addDoubleQuote(userData.getName()));
sb.append(",");
// 生年月日_年
sb.append(userData.getBirth_year());
sb.append(",");
// 生年月日_月
sb.append(userData.getBirth_month());
sb.append(",");
// 生年月日_日
sb.append(userData.getBirth_day());
sb.append(",");
// 性別
sb.append(DemoStringUtil.addDoubleQuote(userData.getSex()));
sb.append(",");
// メモ
sb.append(DemoStringUtil.addDoubleQuote(userData.getMemo()));
return sb.toString();
}
}さらに、Spring Batchのジョブ内で指定する処理単位(ステップ)実行前後の処理を記載したクラスの内容は以下の通りで、ファイルを削除したり、Azure Functions(Linux)に配置したCSVファイルをBlob Storageにアップロードする処理を追加している。
package com.example.batch;
import java.io.File;
import org.springframework.batch.core.ExitStatus;
import org.springframework.batch.core.StepExecution;
import org.springframework.batch.core.StepExecutionListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import com.example.service.DemoBlobService;
@Component
public class DemoStepListener implements StepExecutionListener {
/** BLOBへアクセスするサービス */
@Autowired
private DemoBlobService demoBlobService;
/** 取得したUSER_DATAテーブルのデータを出力するファイルパス */
private static final String TMP_FILE_PATH = "/home/";
/** 取得したUSER_DATAテーブルのデータを出力するファイル名 */
private static final String TMP_FILE_NAME = "tmp_user_data.csv";
/** 取得したUSER_DATAテーブルのデータを出力するBLOB名 */
private static final String BLOB_NAME = "user_data.csv";
/**
* Spring Batchのジョブ内で指定する処理単位(ステップ)実行前の処理を定義する.
*/
@Override
public void beforeStep(StepExecution stepExecution) {
// Blobファイルを削除
demoBlobService.deleteBlockBlob(BLOB_NAME);
// ローカルファイルがあれば削除
// (後続のafterStepメソッドでの削除ができないため、ここで削除)
File tmpFile = new File(TMP_FILE_PATH + TMP_FILE_NAME);
if(tmpFile.exists()) {
tmpFile.delete();
}
}
/**
* Spring Batchのジョブ内で指定する処理単位(ステップ)実行後の処理を定義する.
*/
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
// ローカルファイルをBlobにアップロード
demoBlobService.uploadBlobFromFile(
TMP_FILE_PATH + TMP_FILE_NAME, BLOB_NAME);
return ExitStatus.COMPLETED;
}
}また、BlobStorageにアクセスするクラスの内容は以下の通りで、Blob Storageへのファイルをアップロードや削除処理を追加している。
package com.example.service;
import javax.annotation.PostConstruct;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import com.microsoft.azure.storage.CloudStorageAccount;
import com.microsoft.azure.storage.blob.CloudBlobClient;
import com.microsoft.azure.storage.blob.CloudBlobContainer;
import com.microsoft.azure.storage.blob.CloudBlockBlob;
import io.netty.util.internal.StringUtil;
@Service
public class DemoBlobService {
/** Azure Storageのアカウント名 */
@Value("${azure.storage.accountName}")
private String storageAccountName;
/** Azure Storageへのアクセスキー */
@Value("${azure.storage.accessKey}")
private String storageAccessKey;
/** Azure StorageのBlobコンテナー名 */
@Value("${azure.storage.containerName}")
private String storageContainerName;
// Blobストレージへの接続文字列
private String storageConnectionString = null;
/**
* Blobストレージへの接続文字列の初期化処理
*/
@PostConstruct
public void init() {
// Blobストレージへの接続文字列を設定
storageConnectionString = "DefaultEndpointsProtocol=https;"
+ "AccountName=" + storageAccountName + ";"
+ "AccountKey=" + storageAccessKey + ";";
}
/**
* 引数で指定されたBlobが存在する場合、削除する.
* @param blobName Blob名
*/
public void deleteBlockBlob(String blobName) {
// 未指定の項目がある場合、何もしない
if(StringUtil.isNullOrEmpty(storageAccountName)
|| StringUtil.isNullOrEmpty(storageAccessKey)
|| StringUtil.isNullOrEmpty(storageContainerName)
|| StringUtil.isNullOrEmpty(blobName)) {
return;
}
// Blob内のコンテナー内の指定したファイルが存在する場合、削除する
try {
CloudBlockBlob cbb = getContainer().getBlockBlobReference(blobName);
cbb.deleteIfExists();
} catch (Exception ex) {
throw new RuntimeException(ex);
}
}
/**
* 引数で指定したローカルファイルを、引数で指定されたBlobにアップロードする.
* @param localFile ローカルファイル
* @param blobName Blob名
*/
public void uploadBlobFromFile(String localFile, String blobName) {
// 未指定の項目がある場合、何もしない
if(StringUtil.isNullOrEmpty(storageAccountName)
|| StringUtil.isNullOrEmpty(storageAccessKey)
|| StringUtil.isNullOrEmpty(storageContainerName)
|| StringUtil.isNullOrEmpty(localFile)
|| StringUtil.isNullOrEmpty(blobName)) {
return;
}
try {
CloudBlockBlob cbb = getContainer().getBlockBlobReference(blobName);
cbb.uploadFromFile(localFile);
} catch (Exception ex) {
throw new RuntimeException(ex);
}
}
/**
* Blobストレージのコンテナを取得する.
* @return Blobストレージのコンテナ
* @throws Exception
*/
private CloudBlobContainer getContainer() throws Exception {
// ストレージアカウントオブジェクトを取得
CloudStorageAccount storageAccount
= CloudStorageAccount.parse(storageConnectionString);
// Blobクライアントオブジェクトを取得
CloudBlobClient blobClient
= storageAccount.createCloudBlobClient();
// Blob内のコンテナーを取得
CloudBlobContainer container
= blobClient.getContainerReference(storageContainerName);
return container;
}
}さらに、DBのデータを取得する処理は、以下のMapperで実行している。
package com.example.mybatis;
import java.util.List;
import org.apache.ibatis.annotations.Mapper;
import com.example.mybatis.model.UserData;
@Mapper
public interface UserDataMapper {
/**
* USER_DATAテーブルのデータを全件取得する.
* @return USER_DATAテーブルの全データ
*/
List<UserData> findAll();
}<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mybatis.UserDataMapper">
<select id="findAll" resultType="com.example.mybatis.model.UserData">
SELECT id, name, birth_year, birth_month, birth_day, sex, memo
FROM USER_DATA
<!-- 何件取得するか指定するために、ソート順を指定後に、OFFSET, FETCH NEXTを指定 -->
ORDER BY id ASC
OFFSET #{_skiprows} ROWS
FETCH NEXT #{_pagesize} ROWS ONLY
</select>
</mapper>なお、#{_skiprows}・#{_pagesize}は、MyBatis を利用してデータベースからページ単位でレコードを読み出す、MyBatisPagingItemReaderで利用する変数となる。詳細は以下のサイトを参照のこと。
http://mybatis.org/spring/ja/batch.html
また、文字列の編集処理を定義したクラスの内容は、以下の通り。
package com.example.util;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.time.format.ResolverStyle;
import org.apache.commons.lang3.StringUtils;
public class DemoStringUtil {
/**
* DateTimeFormatterを利用して日付チェックを行う.
* @param dateStr チェック対象文字列
* @param dateFormat 日付フォーマット
* @return 日付チェック結果
*/
public static boolean isCorrectDate(String dateStr, String dateFormat) {
if (StringUtils.isEmpty(dateStr) || StringUtils.isEmpty(dateFormat)) {
return false;
}
// 日付と時刻を厳密に解決するスタイルで、DateTimeFormatterオブジェクトを作成
DateTimeFormatter df = DateTimeFormatter.ofPattern(dateFormat)
.withResolverStyle(ResolverStyle.STRICT);
try {
// チェック対象文字列をLocalDate型の日付に変換できれば、チェックOKとする
LocalDate.parse(dateStr, df);
return true;
} catch (Exception e) {
return false;
}
}
/**
* 数値文字列が1桁の場合、頭に0を付けて返す.
* @param intNum 数値文字列
* @return 変換後数値文字列
*/
public static String addZero(String intNum) {
if (StringUtils.isEmpty(intNum)) {
return intNum;
}
if (intNum.length() == 1) {
return "0" + intNum;
}
return intNum;
}
/**
* 引数の文字列の前後にダブルクォートを追加する.
* ただし、引数の文字列がnullの場合は空文字を返却する.
* @param str 任意の文字列
* @return 変換後文字列
*/
public static String addDoubleQuote(String str) {
String retStr = "";
if(str != null) {
retStr = "\"" + str + "\"";
}
return retStr;
}
}その他のソースコード内容は、以下のサイトを参照のこと。
https://github.com/purin-it/azure/tree/master/azure-functions-db-to-csv/demoAzureFunc

サンプルプログラムの実行結果
サンプルプログラムの実行結果は、以下の通り。
1) 以下のサイトの「サンプルプログラムの実行結果(ローカル)」「サンプルプログラムの実行結果(Azure上)」に記載の手順で、サンプルプログラムをAzure Functionsにデプロイする。

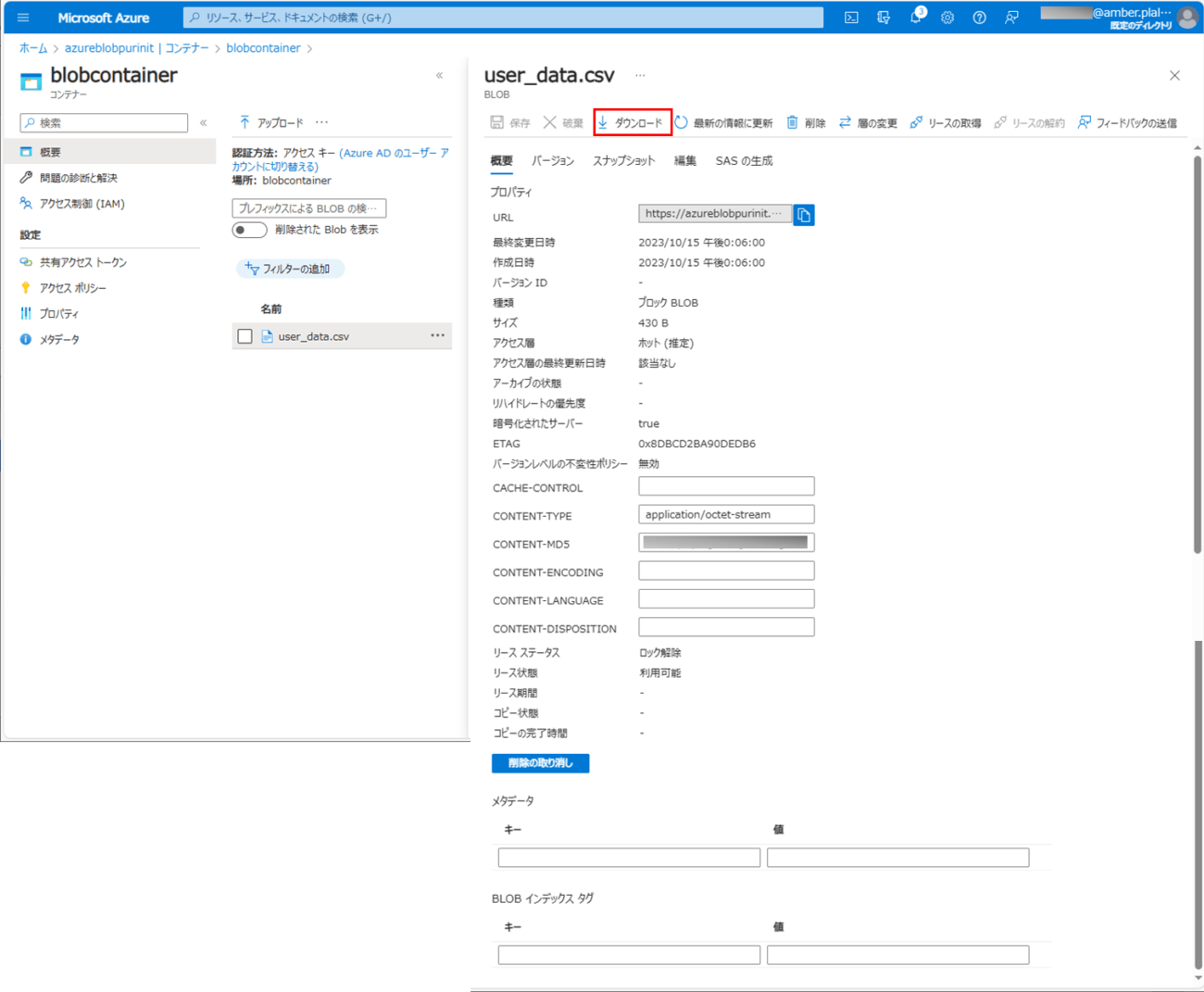
2) バッチ実行後に、Blob Storageに、以下のCSVファイルが出力されていることが確認できる。Blob Storageからファイルをダウンロードするには、一覧のファイルを選択する。
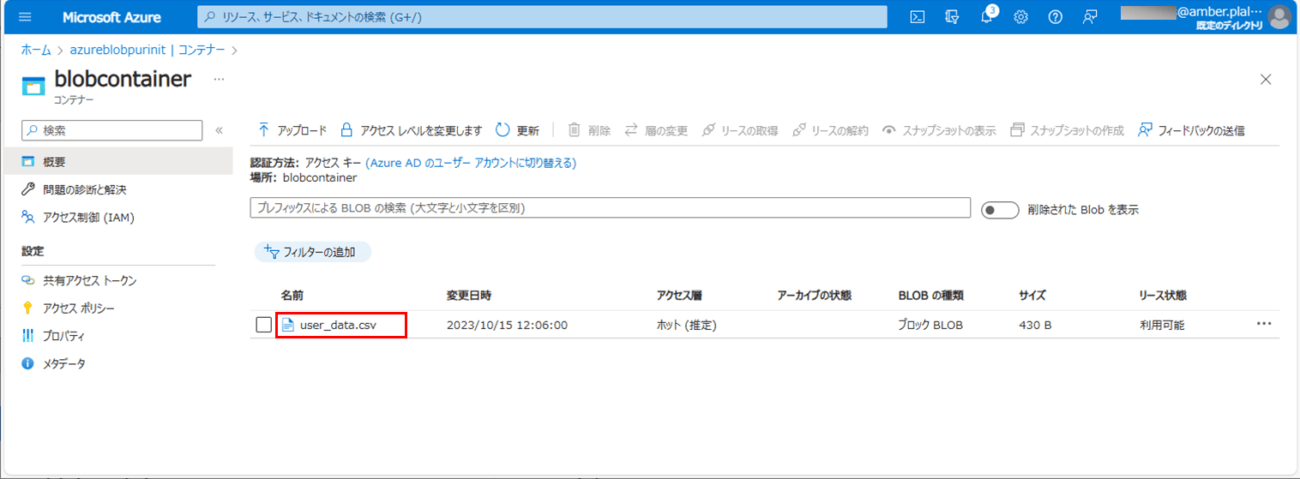
3) ファイルをダウンロードするには、「ダウンロード」ボタンを押下する。
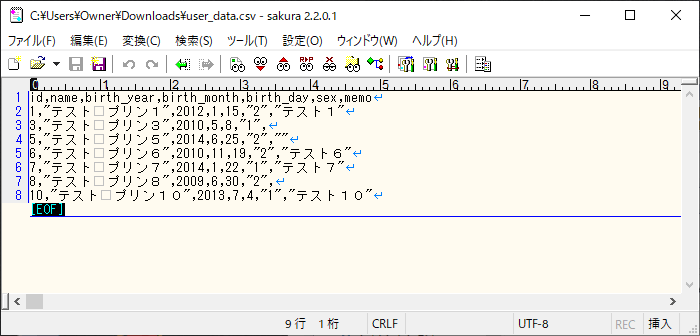
4) 実際にダウンロードされたファイルは、以下の通りで、USER_DATAテーブルのデータ全件が取得できていることが確認できる。
5) バッチ実行時のログ出力内容は、以下の通り。
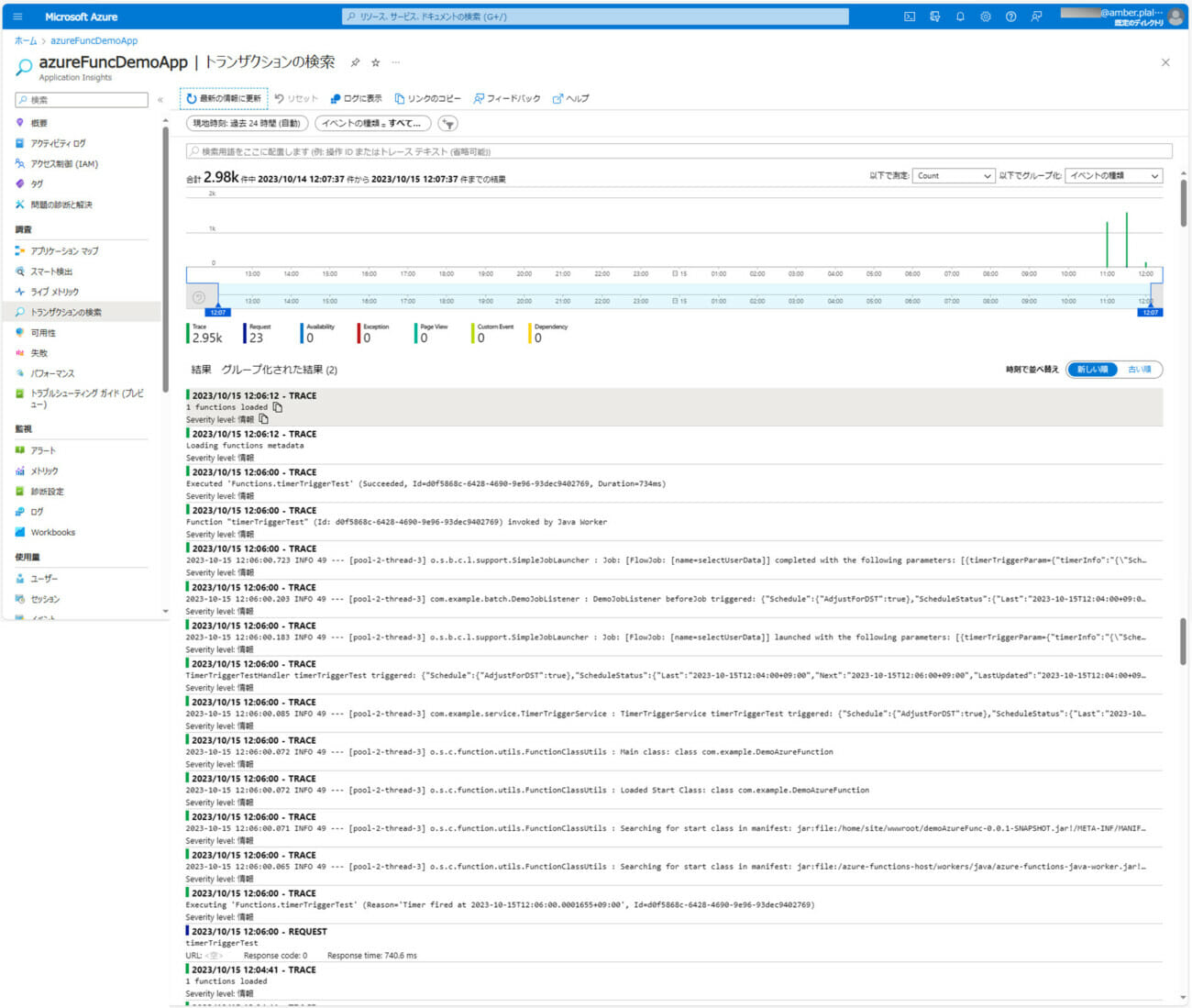
なお、上記ログの確認手順は、以下のサイトを参照のこと。

要点まとめ
- Azure Function上でSpring BatchのChunkモデルを利用すると、Blob上のCSVファイルをDBのテーブルに書き込むだけでなく、DBのテーブルデータをBlob上のCSVファイルに出力することもできる。





