Oracle上でテーブルを結合しデータを取得する際、テーブル別名をつけた場合とつけなかった場合の性能を測定してみた
SQLでテーブルを結合しデータを取得する際、テーブルに別名をつけなくても実行できる場合もあるが、テーブルの別名が無いとSQLの解釈に時間がかかるため、テーブルに別名をつけた方がよい。
今回は、SQLで結合したテーブルのデータを取得する際、テーブルに別名をつけた場合とつけなかった場合それぞれでSQLの実行速度を測定するプログラムを作成してみたので、共有する。
なお、SQL文の性能改善を行う方法については、以下のサイトを参照のこと。
https://sites.google.com/site/orapeform/sql_minaoshi
前提条件
下記記事の実装が完了していること。

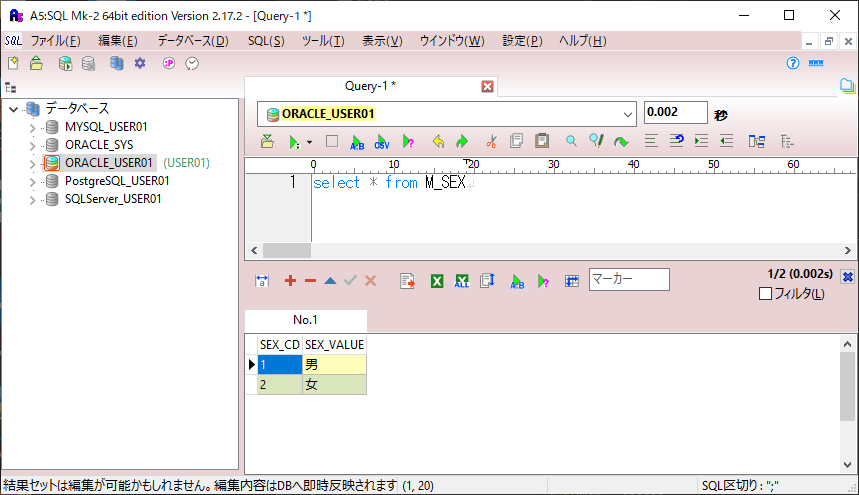
また、USER_DATAテーブルに、上記記事で用意した100,000件のデータが設定されていると共に、M_SEXテーブルに、以下のデータが格納されていること。
サンプルプログラムの作成
作成したサンプルプログラムの構成は、以下の通り。
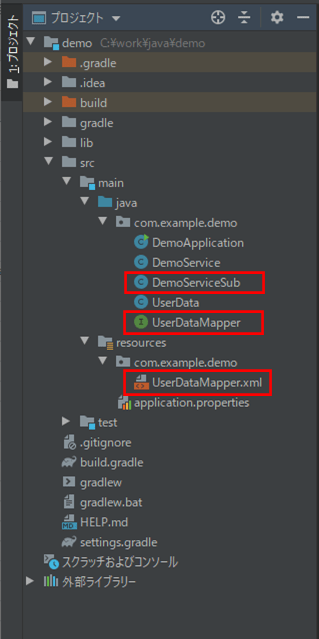
なお、上記の赤枠は、前提条件のプログラムから変更したプログラムである。
Mapperインタフェース・Mapper XMLの内容は以下の通りで、結合するテーブルの別名をつけなかった場合・別名をつけた場合それぞれのデータを取得するSQLを用意している。
package com.example.demo;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
@Mapper
public interface UserDataMapper {
/**
* 指定したIDをもつユーザーデータテーブル(user_data)のデータを取得する
* @param id ID
* @return ユーザーデータテーブル(user_data)の指定したIDのデータ
*/
UserData findById(Long id);
/**
* ユーザーデータテーブル(user_data)と性別テーブル(m_sex)を別名を使わず結合し
* ユーザーデータテーブルのデータを全件取得する
* @return ユーザーデータテーブル(user_data)のリスト
*/
List<UserData> findJoinNoAlias();
/**
* ユーザーデータテーブル(user_data)と性別テーブル(m_sex)を別名を使って結合し
* ユーザーデータテーブルのデータを全件取得する
* @return ユーザーデータテーブル(user_data)のリスト
*/
List<UserData> findJoinAlias();
}<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demo.UserDataMapper">
<resultMap id="userDataResultMap" type="com.example.demo.UserData" >
<id column="id" property="id" jdbcType="BIGINT" />
<result column="name" property="name" jdbcType="VARCHAR" />
<result column="birth_year" property="birthY" jdbcType="VARCHAR" />
<result column="birth_month" property="birthM" jdbcType="VARCHAR" />
<result column="birth_day" property="birthD" jdbcType="VARCHAR" />
<result column="sex" property="sex" jdbcType="VARCHAR" />
<result column="memo" property="memo" jdbcType="VARCHAR" />
</resultMap>
<select id="findById" parameterType="java.lang.Long" resultMap="userDataResultMap">
SELECT id, name, birth_year, birth_month, birth_day, sex, memo
FROM USER_DATA WHERE id = #{id}
</select>
<select id="findJoinNoAlias" parameterType="java.lang.Long"
resultMap="userDataResultMap">
SELECT id, name, birth_year, birth_month, birth_day
, sex_value AS sex, memo
FROM USER_DATA JOIN M_SEX ON USER_DATA.sex = M_SEX.sex_cd
</select>
<select id="findJoinAlias" parameterType="java.lang.Long"
resultMap="userDataResultMap">
SELECT u.id, u.name, u.birth_year, u.birth_month, u.birth_day
, s.sex_value AS sex, u.memo
FROM USER_DATA u JOIN M_SEX s ON u.sex = s.sex_cd
</select>
</mapper>また、サービスクラスのサブクラスの内容は以下の通りで、それぞれのSQLを呼び出し、それぞれの実行時間を表示するようにしている。
package com.example.demo;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class DemoServiceSub {
/**
* ユーザーデータテーブル(user_data)へアクセスするマッパー
*/
@Autowired
private UserDataMapper userDataMapper;
/**
* 性能検証を行うための個別サービス
*/
public void verifyPerformanceEach() {
// 初回DB接続時は時間がかかるため、あえて性能測定対象外のSQLを1度実行しておく
userDataMapper.findById(Long.valueOf(1));
System.out.println("--- ユーザーデータテーブル(user_data)と性別テーブル"
+ "(m_sex)を別名を使わず結合し、ユーザーデータテーブルのデータを"
+ "全件取得するSQLを実行します start. ---");
// 処理前の現在時刻を取得
long startTime = System.currentTimeMillis();
// ユーザーデータテーブル(user_data)と性別テーブル(m_sex)を別名を使わず結合し、
// ユーザーデータテーブルのデータを全件取得する
List<UserData> userDataList = userDataMapper.findJoinNoAlias();
// 処理後の現在時刻を取得
long endTime = System.currentTimeMillis();
System.out.println("取得件数 : " + userDataList.size());
System.out.println("処理時間:" + (endTime - startTime) + " ms");
System.out.println("--- ユーザーデータテーブル(user_data)と性別テーブル"
+ "(m_sex)を別名を使わず結合し、ユーザーデータテーブルのデータを"
+ "全件取得するSQLを実行します end. ---");
System.out.println();
System.out.println("--- ユーザーデータテーブル(user_data)と性別テーブル"
+ "(m_sex)を別名を使って結合し、ユーザーデータテーブルのデータを"
+ "全件取得するSQLを実行します start. ---");
// 処理前の現在時刻を取得
startTime = System.currentTimeMillis();
// ユーザーデータテーブル(user_data)と性別テーブル(m_sex)を別名を使って結合し、
// ユーザーデータテーブルのデータを全件取得する
userDataList = userDataMapper.findJoinAlias();
// 処理後の現在時刻を取得
endTime = System.currentTimeMillis();
System.out.println("取得件数 : " + userDataList.size());
System.out.println("処理時間:" + (endTime - startTime) + " ms");
System.out.println("--- ユーザーデータテーブル(user_data)と性別テーブル"
+ "(m_sex)を別名を使って結合し、ユーザーデータテーブルのデータを"
+ "全件取得するSQLを実行します end. ---");
System.out.println();
}
}その他のソースコード内容は、以下のサイトを参照のこと。
https://github.com/purin-it/java/tree/master/spring-boot-oracle-performance-join/demo
サンプルプログラムの実行結果
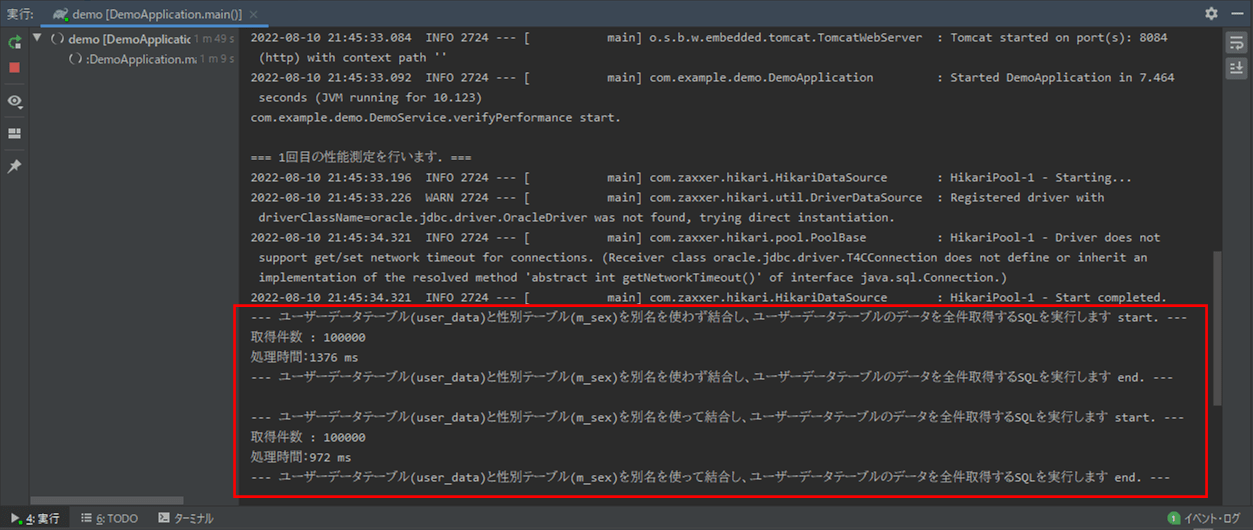
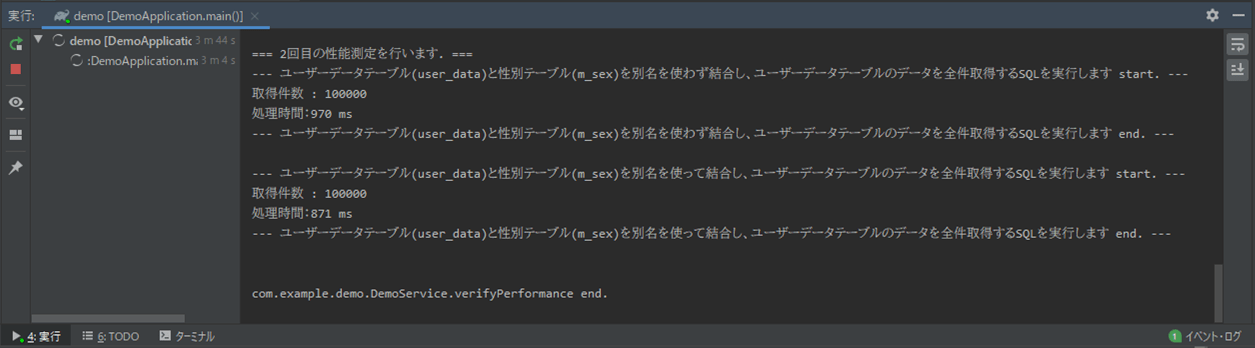
Spring Bootのメインクラス(DemoApplication.java)を実行した結果、コンソールログに出力される内容は以下の通りで、結合するテーブルの別名をつけた方が、SQLが速くなることが確認できる。
要点まとめ
- SQLで結合したテーブルのデータを取得する際、テーブルに別名をつけた方が、SQLの実行速度が速くなる。




