Azure Function上で文字コードCSVファイルのデータ(文字コード:MS932、カンマを含む)をDBに取り込んでみた
これまでこのブログで、Spring BatchのChunkモデルを用いて、Blob上のCSVファイルをDBのテーブルに書き込む処理を作成していたが、その際のCSVファイルの文字コードはUTF-8で、データ内にカンマを含まないものであった。
今回は、読み込むCSVファイルの文字コードをMS932に、データ内にカンマを含むものに変更してみたので、そのサンプルプログラムを共有する。
前提条件
下記記事のサンプルプログラムを作成済であること。

サンプルプログラムの作成
作成したサンプルプログラムの構成は以下の通り。
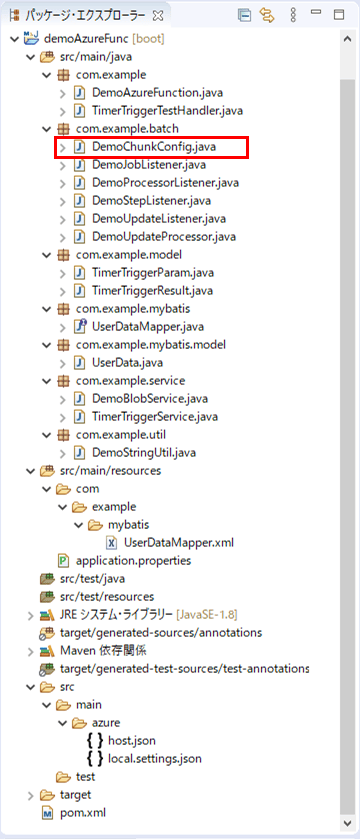
なお、上記の赤枠は、今回変更したプログラムである。
Spring Batchの定義クラスは以下の通りで、readerメソッドについて、文字コードの設定を変更し、区切り文字・囲み文字の設定を追加している。
package com.example.batch;
import java.net.MalformedURLException;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.batch.MyBatisBatchItemWriter;
import org.mybatis.spring.batch.builder.MyBatisBatchItemWriterBuilder;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.UrlResource;
import com.example.mybatis.model.UserData;
import com.example.service.DemoBlobService;
import lombok.RequiredArgsConstructor;
@Configuration
@EnableBatchProcessing
@RequiredArgsConstructor
public class DemoChunkConfig {
/** ジョブ生成ファクトリ */
public final JobBuilderFactory jobBuilderFactory;
/** ステップ生成ファクトリ */
public final StepBuilderFactory stepBuilderFactory;
/** SQLセッションファクトリ */
public final SqlSessionFactory sqlSessionFactory;
/** データ加工処理 */
private final DemoUpdateProcessor demoUpdateProcessor;
/** データ加工前後処理 */
private final DemoProcessorListener demoProcessorListener;
/** データ書き込み前後処理 */
private final DemoUpdateListener demoUpdateListener;
/** ステップの前後処理 */
private final DemoStepListener demoStepListener;
/** BLOBへアクセスするサービス */
@Autowired
private DemoBlobService demoBlobService;
/**
* BlobStorageからファイルを読み込む.
* @return 読み込みオブジェクト
*/
@Bean
public FlatFileItemReader<UserData> reader() {
FlatFileItemReader<UserData> reader = new FlatFileItemReader<UserData>();
try {
// BlobStorageからファイル(user_data.csv)を読み込む際のURLをreaderに設定
String url = demoBlobService.getBlobUrl("user_data.csv");
reader.setResource(new UrlResource(url));
} catch (MalformedURLException ex) {
throw new RuntimeException(ex);
}
// ファイルを読み込む際の文字コード
reader.setEncoding("MS932");
// 1行目を読み飛ばす
reader.setLinesToSkip(1);
// ファイルから読み込んだデータをUserDataオブジェクトに格納
reader.setLineMapper(new DefaultLineMapper<UserData>() {
{
setLineTokenizer(new DelimitedLineTokenizer() {
{
// ファイルから読み込んだデータとUserDataオブジェクトの項目名とのマッピング
setNames(new String[] { "id", "name", "birth_year"
, "birth_month", "birth_day", "sex", "memo" });
// 区切り文字(カンマ)、囲み文字(シングルクォート)
setDelimiter(",");
setQuoteCharacter('\"');
}
});
setFieldSetMapper(new BeanWrapperFieldSetMapper<UserData>() {
{
setTargetType(UserData.class);
}
});
}
});
return reader;
}
/**
* 読み込んだファイルのデータを、DBに書き込む.
* @return 書き込みオブジェクト
*/
@Bean
public MyBatisBatchItemWriter<UserData> writer() {
return new MyBatisBatchItemWriterBuilder<UserData>()
.sqlSessionFactory(sqlSessionFactory)
.statementId("com.example.mybatis.UserDataMapper.upsert")
.assertUpdates(true) // 楽観ロックエラーを有効にする
.build();
}
/**
* Spring Batchのジョブ内で指定する処理単位(ステップ)を定義する.
* @param reader 読み込みオブジェクト
* @param writer 書き込みオブジェクト
* @return Spring Batchのジョブ内で指定する処理単位
*/
@Bean
public Step step(ItemReader<UserData> reader, ItemWriter<UserData> writer) {
// 生成するステップ内で読み込み/加工/加工後/書き込み/書き込み後/ステップ実行前後の処理の
// 一連の流れを指定する
// その際のチャンクサイズ(=何件読み込む毎にコミットするか)を3に指定している
return stepBuilderFactory.get("step")
.<UserData, UserData>chunk(3)
.reader(reader)
.processor(demoUpdateProcessor)
.listener(demoProcessorListener)
.writer(writer)
.listener(demoUpdateListener)
.listener(demoStepListener)
.build();
}
/**
* Spring Batchのジョブを定義する.
* @param jobListener 実行前後の処理(リスナ)
* @param step 実行するステップ
* @return Spring Batchのジョブ
*/
@Bean
public Job updateUserData(DemoJobListener jobListener, Step step) {
// 生成するジョブ内で、実行前後の処理(リスナ)と処理単位(ステップ)を指定する
return jobBuilderFactory
.get("updateUserData")
.incrementer(new RunIdIncrementer())
.listener(jobListener)
.flow(step)
.end()
.build();
}
}その他のソースコード内容は、以下のサイトを参照のこと。
https://github.com/purin-it/azure/tree/master/azure-functions-csv-to-db-ms932-comma/demoAzureFunc

サンプルプログラムの実行結果
サンプルプログラムの実行結果は、以下の通り。
1) 以下のサイトの「サンプルプログラムの実行結果(ローカル)」「サンプルプログラムの実行結果(Azure上)」に記載の手順で、サンプルプログラムをAzure Functionsにデプロイする。

2) 以下の、カンマを含み文字コードがShift_JISで、各項目が囲み文字(ダブルクォート)で囲われたCSVファイルをBlob Storageに配置し、作成したバッチ処理を実行する。
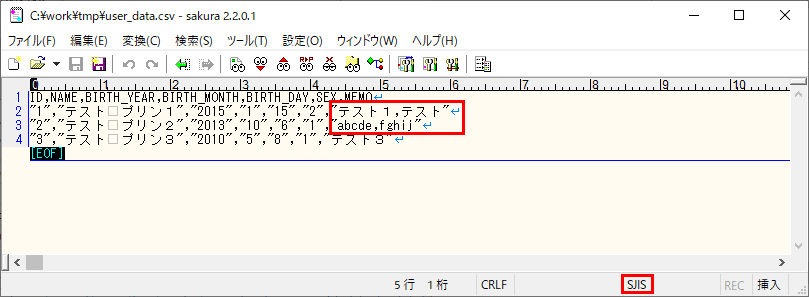
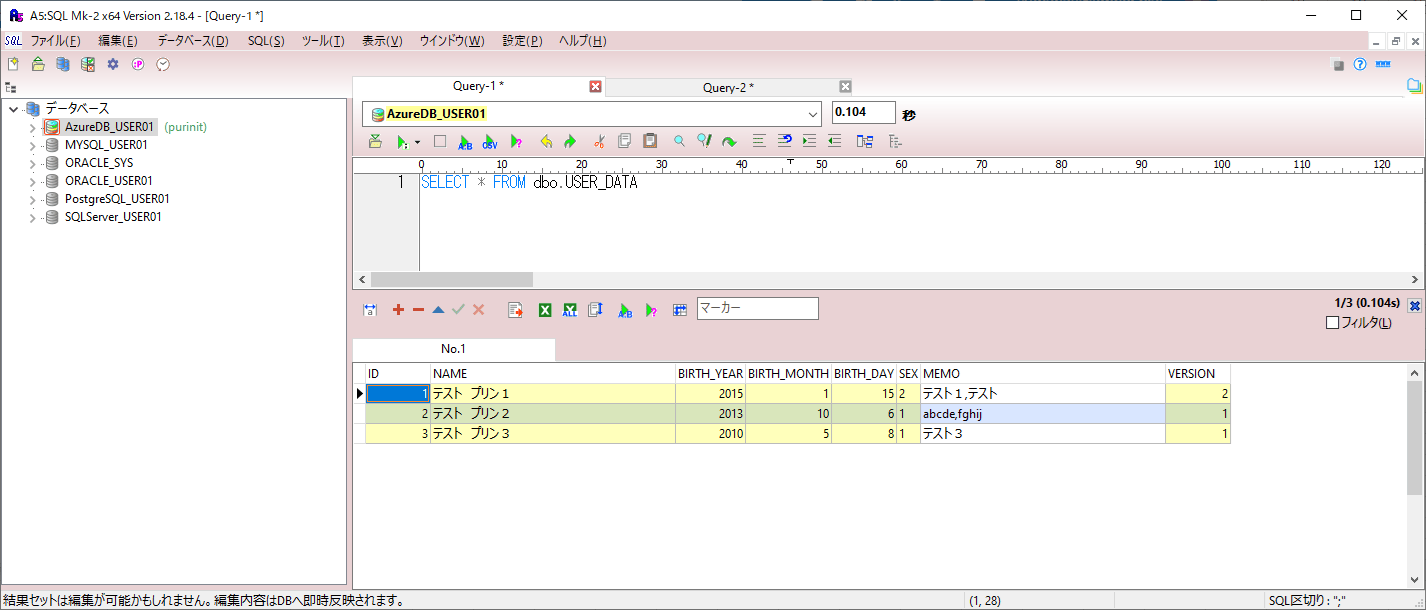
3) バッチ実行後にUSER_DATAテーブルを確認すると、カンマを含み文字コードがShift_JISであるデータが全件登録されていることが確認できる。
要点まとめ
- 文字コードがMS932でカンマを含むCSVファイルのデータであっても、Spring BatchのChunkモデルを用いて、DBのテーブルに書き込むことができる。





