TimerTriggerによって動作するAzure Function上でSpring Batch(Chunkモデル)を利用してみた
これまでは、Spring BatchのTaskletモデルを利用してきたが、ファイルの読み込み/データの加工/DBへの書き込みといった処理の流れを定型化したChunkモデルという方式もある。
Chunkモデルの処理方式については、以下のサイトを参照のこと。
https://spring.pleiades.io/spring-batch/docs/current/reference/html/step.html#chunkOrientedProcessing
今回は、以前作成したプログラムをChunkモデルを利用する方式に変えてみたので、そのサンプルプログラムを共有する。
なお、今回はAzure Blob Storageのファイル読み込み時にSASトークンを発行しないと、ファイルの読み込みを行えないため、以下のサイトに記載されている、SASトークンの生成処理を利用している。
https://logico-jp.io/2021/01/21/create-a-service-sas-for-a-container-or-blob-storage-in-java/
前提条件
下記記事のサンプルプログラムを作成済であること。

また、読み込むCSVファイルの文字コードはUTF-8であるものとする。
作成したサンプルプログラムの修正
前提条件の記事のサンプルプログラムを、Chunkモデルを利用するように修正する。なお、下記の赤枠は、前提条件のプログラムから変更したり、追加したりしたプログラムである。
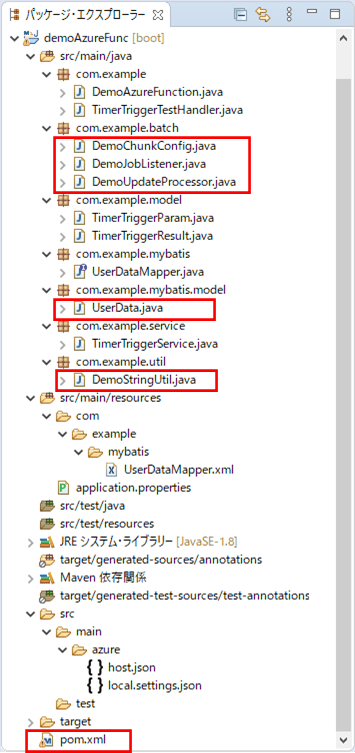
Chunkモデルの設定を行うクラスの内容は以下の通りで、ファイルの読み込み・DBへの書き込みや、バッチ処理単位(ステップ)やジョブの定義を行っている。
package com.example.batch;
import java.net.MalformedURLException;
import javax.sql.DataSource;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.batch.MyBatisBatchItemWriter;
import org.mybatis.spring.batch.builder.MyBatisBatchItemWriterBuilder;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.UrlResource;
import com.azure.storage.blob.BlobServiceClient;
import com.azure.storage.blob.BlobServiceClientBuilder;
import com.example.mybatis.model.UserData;
import com.example.util.DemoStringUtil;
import lombok.RequiredArgsConstructor;
@Configuration
@EnableBatchProcessing
@RequiredArgsConstructor
public class DemoChunkConfig {
public final JobBuilderFactory jobBuilderFactory;
public final StepBuilderFactory stepBuilderFactory;
public final SqlSessionFactory sqlSessionFactory;
private final DemoUpdateProcessor demoUpdateProcessor;
/** Azure Storageのアカウント名 */
@Value("${azure.storage.accountName}")
private String storageAccountName;
/** Azure Storageへのアクセスキー */
@Value("${azure.storage.accessKey}")
private String storageAccessKey;
/** Azure StorageのBlobコンテナー名 */
@Value("${azure.storage.containerName}")
private String storageContainerName;
/**
* BlobStorageからファイルを読み込む.
* @return 読み込みオブジェクト
*/
@Bean
public FlatFileItemReader<UserData> reader() {
FlatFileItemReader<UserData> reader = new FlatFileItemReader<UserData>();
try {
// Blobストレージへの接続文字列
String storageConnectionString = "DefaultEndpointsProtocol=https;"
+ "AccountName=" + storageAccountName
+ ";" + "AccountKey=" + storageAccessKey + ";";
// Blobサービスクライアントの生成
BlobServiceClient blobServiceClient = new BlobServiceClientBuilder()
.connectionString(storageConnectionString).buildClient();
// BlobサービスクライアントからSASを生成
String sas = DemoStringUtil.getServiceSasUriForBlob(blobServiceClient);
// BlobStorageからファイル(user_data.csv)を読み込む際のURLをreaderに設定
String url = blobServiceClient.getAccountUrl() + "/"
+ storageContainerName + "/user_data.csv"
+ "?" + sas;
reader.setResource(new UrlResource(url));
} catch (MalformedURLException ex) {
throw new RuntimeException(ex);
}
// ファイルを読み込む際の文字コード
reader.setEncoding("UTF-8");
// 1行目を読み飛ばす
reader.setLinesToSkip(1);
// ファイルから読み込んだデータをUserDataオブジェクトに格納
reader.setLineMapper(new DefaultLineMapper<UserData>() {
{
setLineTokenizer(new DelimitedLineTokenizer() {
{
setNames(new String[] { "id", "name", "birth_year"
, "birth_month", "birth_day", "sex", "memo" });
}
});
setFieldSetMapper(new BeanWrapperFieldSetMapper<UserData>() {
{
setTargetType(UserData.class);
}
});
}
});
return reader;
}
/**
* 読み込んだファイルのデータを、DBに書き込む.
* @param dataSource データソース
* @return 書き込みオブジェクト
*/
@Bean
public MyBatisBatchItemWriter<UserData> writer(DataSource dataSource) {
return new MyBatisBatchItemWriterBuilder<UserData>()
.sqlSessionFactory(sqlSessionFactory)
.statementId("com.example.mybatis.UserDataMapper.upsert")
.build();
}
/**
* Spring Batchのジョブ内で指定する処理単位(ステップ)を定義する.
* @param reader 読み込みオブジェクト
* @param writer 書き込みオブジェクト
* @return Spring Batchのジョブ内で指定する処理単位
*/
@Bean
public Step step(ItemReader<UserData> reader, ItemWriter<UserData> writer) {
// 生成するステップ内で読み込み/加工/書き込みを一連の流れを指定する
// その際のチャンクサイズ(=何件読み込む毎にコミットするか)を3に指定している
return stepBuilderFactory.get("step")
.<UserData, UserData>chunk(3)
.reader(reader)
.processor(demoUpdateProcessor)
.writer(writer)
.build();
}
/**
* Spring Batchのジョブを定義する.
* @param jobListener 実行前後の処理(リスナ)
* @param step 実行するステップ
* @return Spring Batchのジョブ
*/
@Bean
public Job updateUserData(DemoJobListener jobListener, Step step) {
// 生成するジョブ内で、実行前後の処理(リスナ)と処理単位(ステップ)を指定する
return jobBuilderFactory
.get("updateUserData")
.incrementer(new RunIdIncrementer())
.listener(jobListener)
.flow(step)
.end()
.build();
}
}
また、読み込んだデータのチェックを行うクラスの内容は以下の通りで、エラー時はログ出力し、(DBへの書き込みをしないよう)NULLを返却するようにしている。
package com.example.batch;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.stereotype.Component;
import com.example.mybatis.model.UserData;
import com.example.util.DemoStringUtil;
@Component
public class DemoUpdateProcessor implements ItemProcessor<UserData, UserData> {
/* Spring Bootでログ出力するためのLogbackのクラスを生成 */
private static final Logger LOGGER
= LoggerFactory.getLogger(DemoUpdateProcessor.class);
/**
* 読み込んだデータの加工を行う.
* ここでは、読み込んだデータのチェックを行い、エラーがあればNULLを、
* エラーがなければ引数の値をそのまま返す.
*/
@Override
public UserData process(UserData item) throws Exception {
String itemId = item.getId();
// 1列目が空またはNULLの場合はエラー
if (StringUtils.isEmpty(itemId)) {
LOGGER.info("1列目が空またはNULLです。");
return null;
}
// 1列目が数値以外の場合はエラー
if (!StringUtils.isNumeric(itemId)) {
LOGGER.info("1列目が数値以外です。" + " 該当のid=" + itemId);
return null;
}
// 1列目の桁数が不正な場合はエラー
if (itemId.length() > 6) {
LOGGER.info("1列目の桁数が不正です。" + " 該当のid=" + itemId);
return null;
}
// 2列目が空またはNULLの場合はエラー
if (StringUtils.isEmpty(item.getName())) {
LOGGER.info("2列目が空またはNULLです。" + " 該当のid=" + itemId);
return null;
}
// 2列目の桁数が不正な場合はエラー
if (item.getName().length() > 40) {
LOGGER.info("2列目の桁数が不正です。" + " 該当のid=" + itemId);
return null;
}
// 3列目が空またはNULLの場合はエラー
if (StringUtils.isEmpty(item.getBirth_year())) {
LOGGER.info("3列目が空またはNULLです。" + " 該当のid=" + itemId);
return null;
}
// 3列目が数値以外の場合はエラー
if (!StringUtils.isNumeric(item.getBirth_year())) {
LOGGER.info("3列目が数値以外です。" + " 該当のid=" + itemId);
return null;
}
// 3列目の桁数が不正な場合はエラー
if (item.getBirth_year().length() > 4) {
LOGGER.info("3列目の桁数が不正です。" + " 該当のid=" + itemId);
return null;
}
// 4列目が空またはNULLの場合はエラー
if (StringUtils.isEmpty(item.getBirth_month())) {
LOGGER.info("4列目が空またはNULLです。" + " 該当のid=" + itemId);
return null;
}
// 4列目が数値以外の場合はエラー
if (!StringUtils.isNumeric(item.getBirth_month())) {
LOGGER.info("4列目が数値以外です。" + " 該当のid=" + itemId);
return null;
}
// 4列目の桁数が不正な場合はエラー
if (item.getBirth_month().length() > 4) {
LOGGER.info("4列目の桁数が不正です。" + " 該当のid=" + itemId);
return null;
}
// 5列目が空またはNULLの場合はエラー
if (StringUtils.isEmpty(item.getBirth_day())) {
LOGGER.info("5列目が空またはNULLです。" + " 該当のid=" + itemId);
return null;
}
// 5列目が数値以外の場合はエラー
if (!StringUtils.isNumeric(item.getBirth_day())) {
LOGGER.info("5列目が数値以外です。"+ " 該当のid=" + itemId);
return null;
}
// 5列目の桁数が不正な場合はエラー
if (item.getBirth_day().length() > 2) {
LOGGER.info(" 5列目の桁数が不正です。"+ " 該当のid=" + itemId);
return null;
}
// 3列目・4列目・5列目から生成される日付が不正であればエラー
String birthDay = item.getBirth_year()
+ DemoStringUtil.addZero(item.getBirth_month())
+ DemoStringUtil.addZero(item.getBirth_day());
if (!DemoStringUtil.isCorrectDate(birthDay, "uuuuMMdd")) {
LOGGER.info("3~5列目の日付が不正です。"+ " 該当のid=" + itemId);
return null;
}
// 6列目が1,2以外の場合はエラー
if (!("1".equals(item.getSex()))
&& !("2".equals(item.getSex()))) {
LOGGER.info("6列目の性別が不正です。"+ " 該当のid=" + itemId);
return null;
}
// 7列目の桁数が不正な場合はエラー
if (!StringUtils.isEmpty(item.getMemo())
&& item.getMemo().length() > 1024) {
LOGGER.info("7列目の桁数が不正です。"+ " 該当のid=" + itemId);
return null;
}
return item;
}
}さらに、ジョブの実行前後に処理を追加するクラスの内容は以下の通りで、@Componentアノテーションを付与してDemoChunkConfigクラスから参照できるようにしている。
package com.example.batch;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.listener.JobExecutionListenerSupport;
import org.springframework.stereotype.Component;
import com.example.model.TimerTriggerParam;
import com.fasterxml.jackson.core.type.TypeReference;
import com.fasterxml.jackson.databind.ObjectMapper;
@Component
public class DemoJobListener extends JobExecutionListenerSupport {
/* Spring Bootでログ出力するためのLogbackのクラスを生成 */
private static final Logger LOGGER
= LoggerFactory.getLogger(DemoJobListener.class);
/**
* Spring Batchのジョブ実行前の処理を定義する.
*/
@Override
public void beforeJob(JobExecution jobExecution) {
super.beforeJob(jobExecution);
// Spring Batchのジョブ実行前の処理が呼び出されたことをログ出力する
printLog(jobExecution, "beforeJob");
}
/**
* Spring Batchのジョブ実行後の処理を定義する.
*/
@Override
public void afterJob(JobExecution jobExecution) {
super.afterJob(jobExecution);
// Spring Batchのジョブ実行後の処理が呼び出されたことをログ出力する
printLog(jobExecution, "afterJob");
}
/**
* ログ出力を行う.
* @param jobExecution ジョブ実行時の定義オブジェクト
* @param methodName メソッド名
*/
private void printLog(JobExecution jobExecution, String methodName) {
try {
String paramStr
= jobExecution.getJobParameters().getString("timerTriggerParam");
if(paramStr != null) {
TimerTriggerParam param = new ObjectMapper().readValue(
paramStr, new TypeReference<TimerTriggerParam>() {});
LOGGER.info("DemoJobListener " + methodName
+ " triggered: " + param.getTimerInfo());
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
また、UserDataクラスの内容は以下の通りで、全項目を文字列型に変更している。
package com.example.mybatis.model;
import lombok.Data;
@Data
public class UserData {
/** ID */
private String id;
/** 名前 */
private String name;
/** 生年月日_年 */
private String birth_year;
/** 生年月日_月 */
private String birth_month;
/** 生年月日_日 */
private String birth_day;
/** 性別 */
private String sex;
/** メモ */
private String memo;
}さらに、pom.xmlの追加内容は以下の通りで、SASトークンを生成するための設定を追加している。
<!-- Azure StorageでSASトークンを利用するための設定 -->
<dependency>
<groupId>com.azure</groupId>
<artifactId>azure-storage-blob</artifactId>
<version>12.10.0</version>
</dependency>また、文字列を編集するユーティリティクラスの内容は以下の通りで、SASトークンを生成するgetServiceSasUriForBlobメソッドを追加している。
package com.example.util;
import java.time.Duration;
import java.time.LocalDate;
import java.time.OffsetDateTime;
import java.time.format.DateTimeFormatter;
import java.time.format.ResolverStyle;
import org.apache.commons.lang3.StringUtils;
import com.azure.storage.blob.BlobServiceClient;
import com.azure.storage.common.sas.AccountSasPermission;
import com.azure.storage.common.sas.AccountSasResourceType;
import com.azure.storage.common.sas.AccountSasService;
import com.azure.storage.common.sas.AccountSasSignatureValues;
public class DemoStringUtil {
/**
* DateTimeFormatterを利用して日付チェックを行う.
* @param dateStr チェック対象文字列
* @param dateFormat 日付フォーマット
* @return 日付チェック結果
*/
public static boolean isCorrectDate(String dateStr, String dateFormat) {
if (StringUtils.isEmpty(dateStr) || StringUtils.isEmpty(dateFormat)) {
return false;
}
// 日付と時刻を厳密に解決するスタイルで、DateTimeFormatterオブジェクトを作成
DateTimeFormatter df = DateTimeFormatter.ofPattern(dateFormat)
.withResolverStyle(ResolverStyle.STRICT);
try {
// チェック対象文字列をLocalDate型の日付に変換できれば、チェックOKとする
LocalDate.parse(dateStr, df);
return true;
} catch (Exception e) {
return false;
}
}
/**
* 数値文字列が1桁の場合、頭に0を付けて返す.
* @param intNum 数値文字列
* @return 変換後数値文字列
*/
public static String addZero(String intNum) {
if (StringUtils.isEmpty(intNum)) {
return intNum;
}
if (intNum.length() == 1) {
return "0" + intNum;
}
return intNum;
}
/**
* 引数で指定したBlobのSASトークンを生成し返す.
* @param client Blobサービスクライアントオブジェクト
* @return SASトークン
*/
public static String getServiceSasUriForBlob(BlobServiceClient client) {
// SASトークンのアクセス権を読み取り可能に設定
AccountSasPermission permissions
= new AccountSasPermission().setReadPermission(true);
// SASトークンがBlobコンテナやオブジェクトにアクセスできるように設定
AccountSasResourceType resourceTypes
= new AccountSasResourceType().setContainer(true).setObject(true);
// SASトークンがBlobにアクセスできるように設定
AccountSasService services = new AccountSasService().setBlobAccess(true);
// SASトークンの有効期限を5分に設定
OffsetDateTime expiryTime = OffsetDateTime.now().plus(Duration.ofMinutes(5));
// SASトークンを作成
AccountSasSignatureValues sasValues = new AccountSasSignatureValues(
expiryTime, permissions, services, resourceTypes);
return client.generateAccountSas(sasValues);
}
}その他のソースコード内容は、以下のサイトを参照のこと。
https://github.com/purin-it/azure/tree/master/azure-functions-spring-batch-chunk/demoAzureFunc
サンプルプログラムの実行結果
サンプルプログラムの実行結果は、以下の通り。
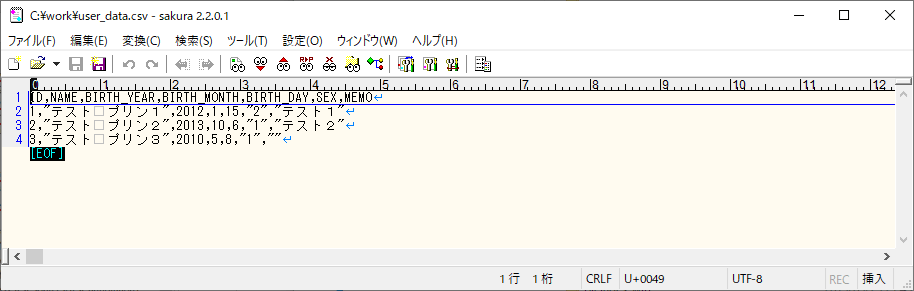
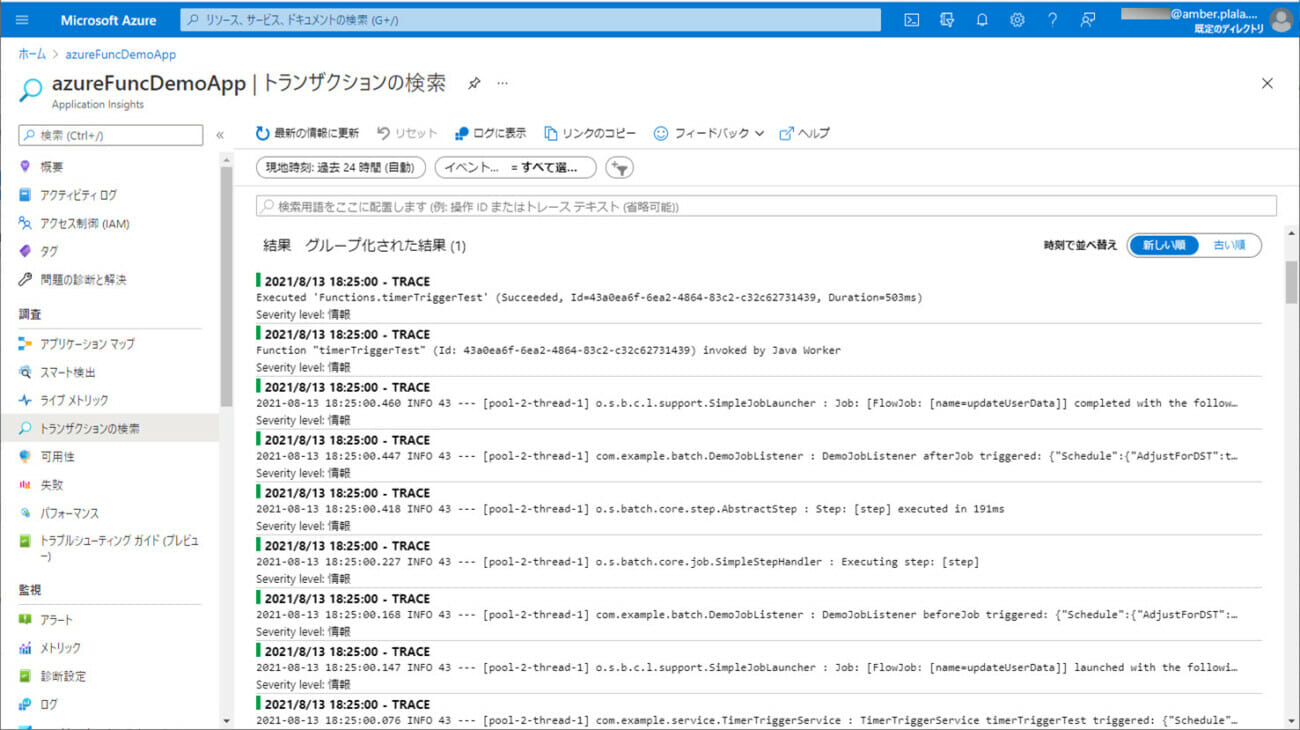
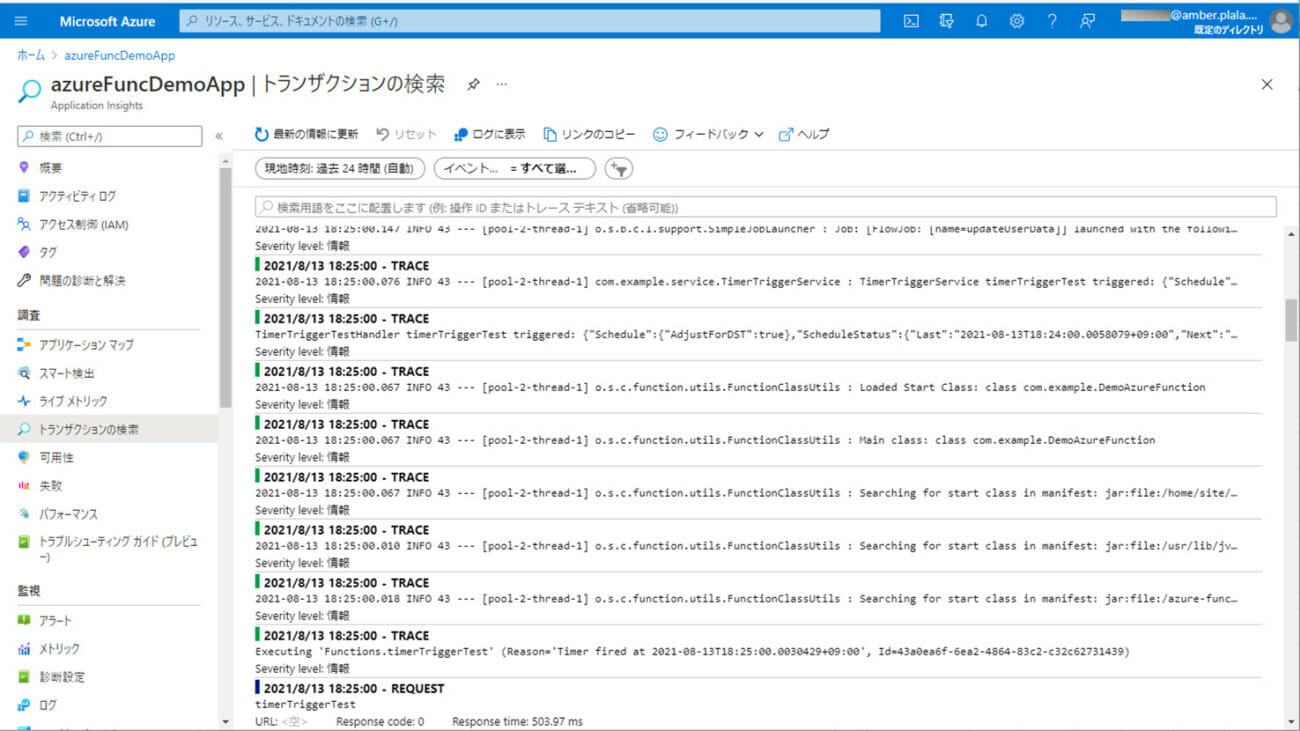
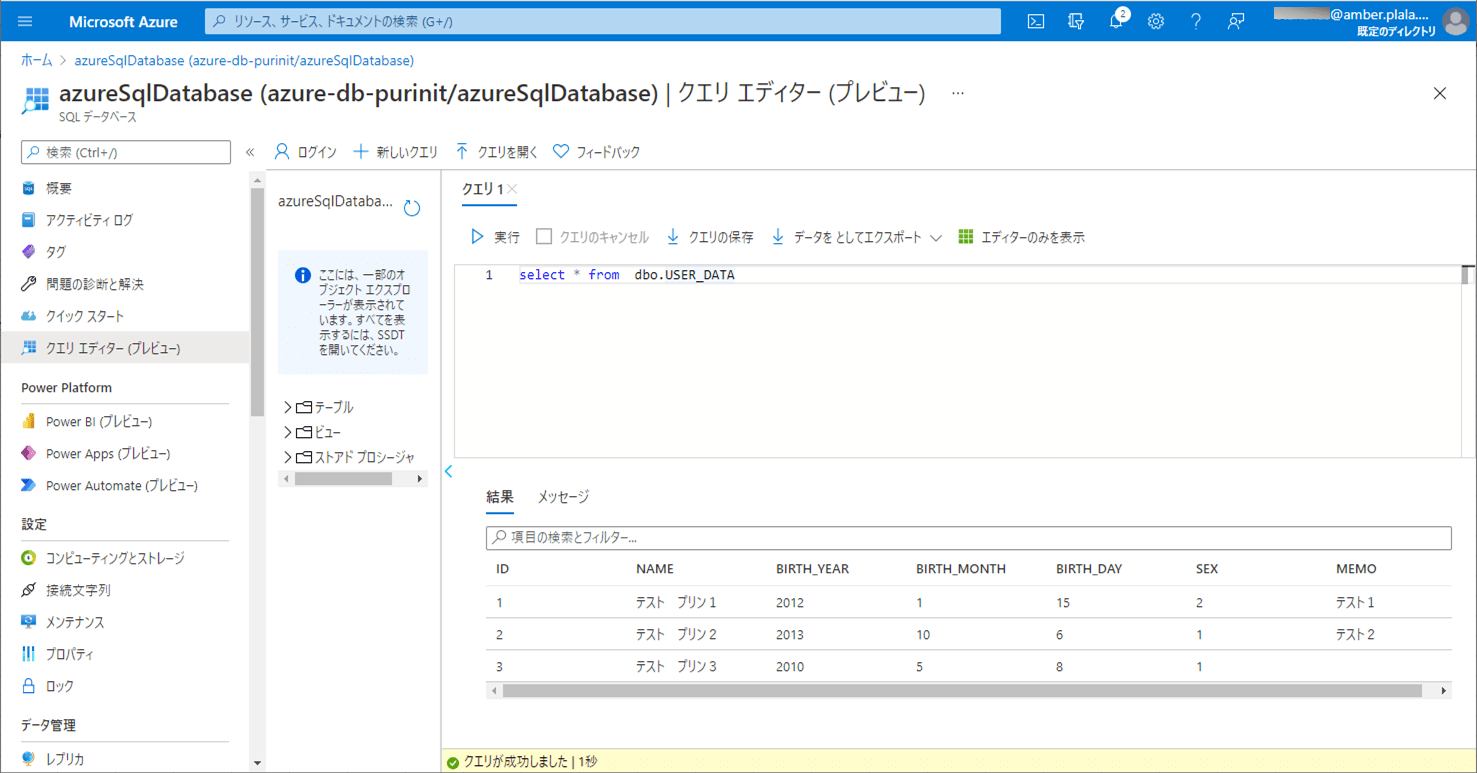
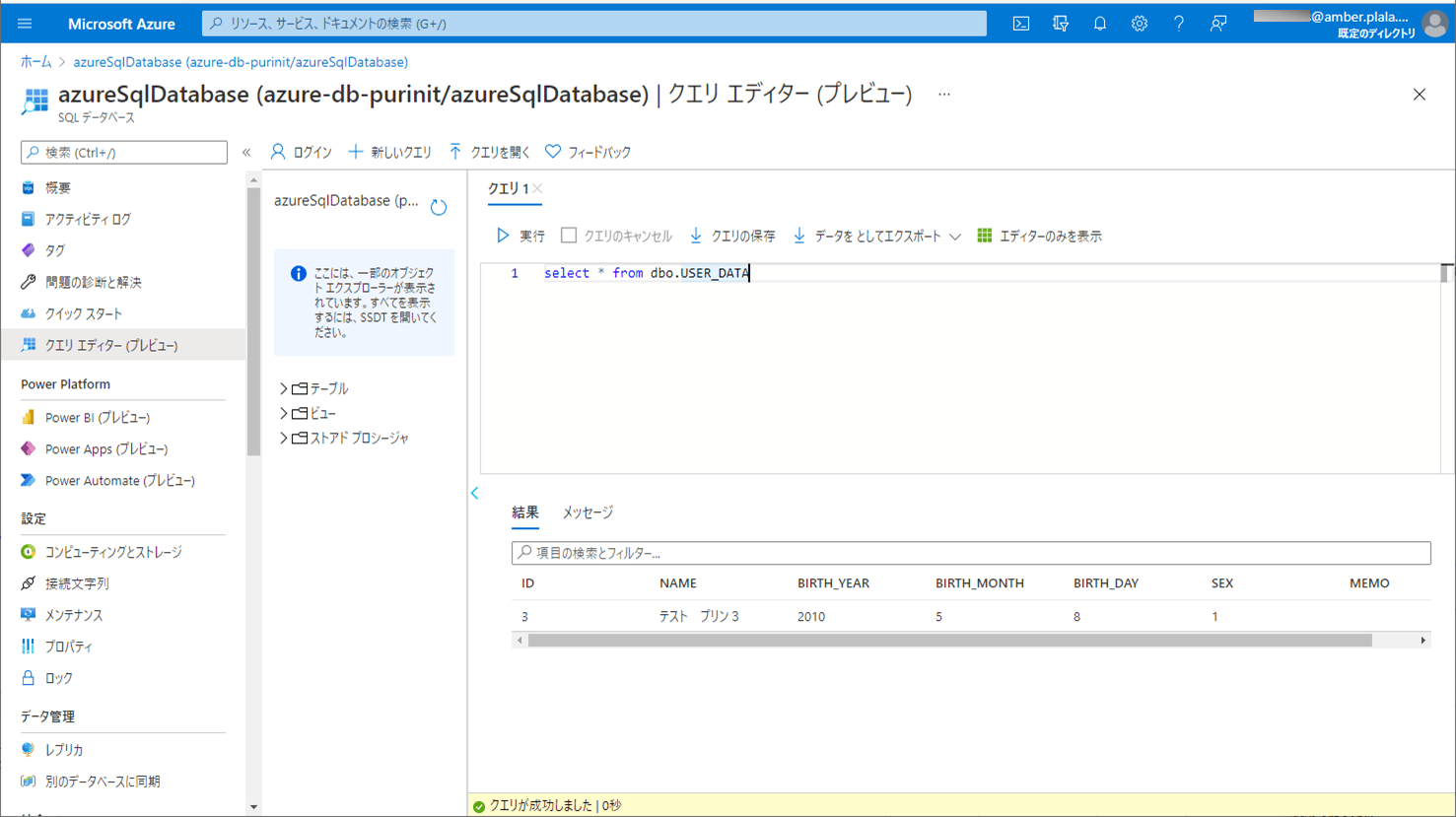
1) エラーが発生しない場合のCSVファイル・ログ・取り込み後のDBの内容は以下の通りで、CSVファイルの内容が、SQLデータベース上のUSER_DATAテーブルに全て取り込まれたことが確認できる。
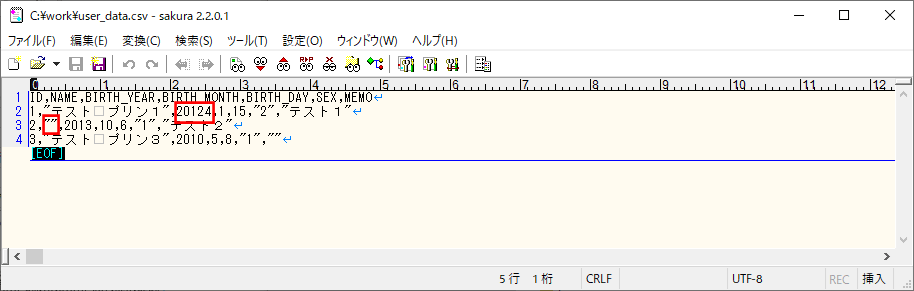
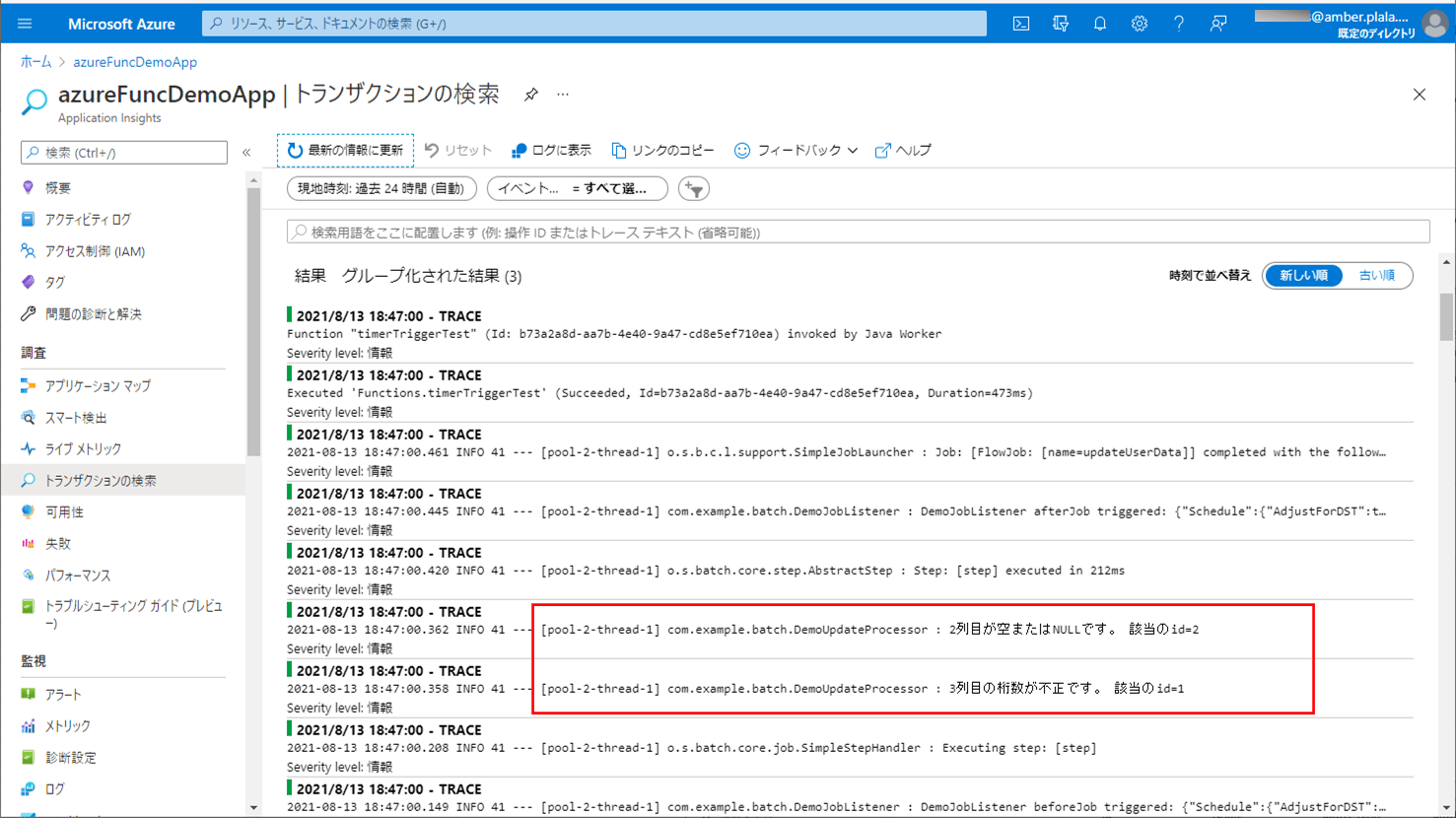
2) 赤枠でエラーが発生する場合のCSVファイル・ログ・取り込み後のDBの内容は以下の通りで、ログにエラー内容が出力され、SQLデータベース上のUSER_DATAテーブルに、エラーでないid=3のデータのみ取り込まれたことが確認できる。
要点まとめ
- Azure Functions上でSpring Batchを利用する際、TaskletモデルだけでなくChunkモデルも利用できる。
- Chunkモデルでは、ファイルの読み込み/データの加工/DBへの書き込みといった処理の流れを定型化している。
- ChunkモデルでAzure Blob Storageのファイル読み込む際は、SASトークンを発行する必要がある。





