scikit-learnのtrain_test_splitメソッドで入力データを分割してみた
Python で利用できるデータ分析や機械学習のためのライブラリの一つであるscikit-learnには、(回帰直線の算出元である)入力データを、訓練用データとテストデータに分割できるtrain_test_splitメソッドがあり、これを利用すると、訓練用データから生成した回帰直線を、テストデータを利用して検証することができる。
今回は、scikit-learnのtrain_test_splitメソッドを用いて、入力データを、訓練用データとテストデータに分割し検証してみたので、そのサンプルプログラムを共有する。
scikit-learnのtrain_test_splitメソッドを用いて、(回帰直線の算出元である)入力データを、訓練用データとテストデータに分割した結果は、以下の通り。
import numpy as np
from sklearn.model_selection import train_test_split
# 入力データの読み込み
input_data = np.array([[33,352], [33,324], [34,338], [34,317], [35,341],
[35,360], [34,339], [32,329], [28,283], [35,372],
[33,342], [28,262], [32,328], [33,326], [35,354],
[30,294], [29,275], [32,336], [34,354], [35,368]])
# 入力データのx座標、y座標の抜き出し
input_data_x = input_data[:, 0]
input_data_y = input_data[:, 1]
# 入力データを訓練用とテスト用で分割
# test_sizeには、テストデータの割合を指定する
# random_stateを指定することで、分割方法を固定できる
train_data_x, test_data_x, train_data_y, test_data_y \
= train_test_split(input_data_x, input_data_y, test_size=0.2, random_state=0)
# 分割した各データを表示
print("*** 訓練用データ x座標 ***")
print(train_data_x)
print("*** 訓練用データ y座標 ***")
print(train_data_y)
print("*** テスト用データ x座標 ***")
print(test_data_x)
print("*** テスト用データ y座標 ***")
print(test_data_y)
なお、train_test_splitメソッドでrandom_stateを指定すると、実行結果は上記の内容で毎回固定になるが、random_stateを指定しないと、以下のように、実行する度に、訓練用とテスト用のデータ分割内容が異なっている。
import numpy as np
from sklearn.model_selection import train_test_split
# 入力データの読み込み
input_data = np.array([[33,352], [33,324], [34,338], [34,317], [35,341],
[35,360], [34,339], [32,329], [28,283], [35,372],
[33,342], [28,262], [32,328], [33,326], [35,354],
[30,294], [29,275], [32,336], [34,354], [35,368]])
# 入力データのx座標、y座標の抜き出し
input_data_x = input_data[:, 0]
input_data_y = input_data[:, 1]
# 入力データを訓練用とテスト用で分割
# test_sizeには、テストデータの割合を指定する
# random_stateを指定することで、分割方法を固定できる
train_data_x, test_data_x, train_data_y, test_data_y \
= train_test_split(input_data_x, input_data_y, test_size=0.2)
# 分割した各データを表示
print("*** 訓練用データ x座標 ***")
print(train_data_x)
print("*** 訓練用データ y座標 ***")
print(train_data_y)
print("*** テスト用データ x座標 ***")
print(test_data_x)
print("*** テスト用データ y座標 ***")
print(test_data_y)●1回目の実行結果

●2回目の実行結果

●3回目の実行結果


また、scikit-learnのtrain_test_splitメソッドを用いて、訓練用データ・テストデータを分割した後に、回帰直線を算出しグラフ化した結果は、以下の通り。
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import linear_model
# 入力データの読み込み
input_data = np.array([[33,352], [33,324], [34,338], [34,317], [35,341],
[35,360], [34,339], [32,329], [28,283], [35,372],
[33,342], [28,262], [32,328], [33,326], [35,354],
[30,294], [29,275], [32,336], [34,354], [35,368]])
# 入力データのx座標、y座標の抜き出し
input_data_x = input_data[:, 0]
input_data_y = input_data[:, 1]
# 入力データを訓練用とテスト用で分割
# test_sizeには、テストデータの割合を指定する
# random_stateを指定することで、分割方法を固定できる
train_data_x, test_data_x, train_data_y, test_data_y \
= train_test_split(input_data_x, input_data_y, test_size=0.2, random_state=0)
# LinearRegressionクラスを利用するため、抜き出したtrain_dataの
# x座標・y座標を、2次元1列の配列とする縦ベクトルに変更
train_data_x = train_data_x.reshape(-1, 1)
train_data_y = train_data_y.reshape(-1, 1)
# train_dataの値から、回帰直線を算出
clf = linear_model.LinearRegression()
clf.fit(train_data_x, train_data_y)
# 算出した回帰直線のa,bの値
a = clf.coef_[0][0]
b = clf.intercept_[0]
print("*** a,bの値 ***")
print("a = " + str(a) + ", b = " + str(b))
# train_dataの値を散布図で表示
train_data_x = train_data_x.reshape(1, -1)
train_data_y = train_data_y.reshape(1, -1)
plt.scatter(input_data_x, input_data_y)
plt.title("train_data")
plt.xlabel("x", size=14)
plt.ylabel("y", size=14)
plt.xlim(26, 36)
plt.ylim(0, 450)
plt.grid()
# 算出した直線(y = ax + b)を追加で表示
x = np.linspace(26, 36, 1000)
y = a * x + b
plt.plot(x, y, label='y = ax+b', color='darkviolet')
plt.legend()
plt.show()
# test_dataの値を散布図で表示
test_data_x = test_data_x.reshape(1, -1)
test_data_y = test_data_y.reshape(1, -1)
plt.scatter(test_data_x, test_data_y)
plt.title("test_data")
plt.xlabel("x", size=14)
plt.ylabel("y", size=14)
plt.xlim(26, 36)
plt.ylim(0, 450)
plt.grid()
# 算出した直線(y = ax + b)を追加で表示
x = np.linspace(26, 36, 1000)
y = a * x + b
plt.plot(x, y, label='y = ax+b', color='darkviolet')
plt.legend()
plt.show()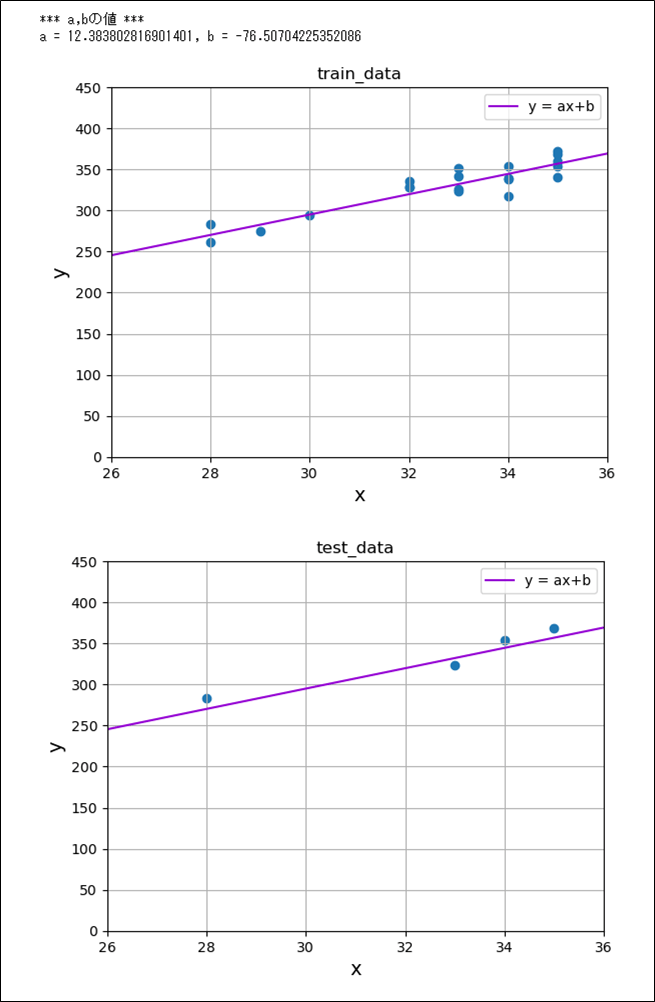
さらに、scikit-learnのtrain_test_splitメソッドを用いて、訓練用データ・テストデータを分割した後に回帰直線を算出し、テストデータからy座標を予測した結果と実際のデータを比較した結果は、以下の通り。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import linear_model
# 入力データの読み込み
input_data = np.array([[33,352], [33,324], [34,338], [34,317], [35,341],
[35,360], [34,339], [32,329], [28,283], [35,372],
[33,342], [28,262], [32,328], [33,326], [35,354],
[30,294], [29,275], [32,336], [34,354], [35,368]])
# 入力データのx座標、y座標の抜き出し
input_data_x = input_data[:, 0]
input_data_y = input_data[:, 1]
# 入力データを訓練用とテスト用で分割
# test_sizeには、テストデータの割合を指定する
# random_stateを指定することで、分割方法を固定できる
train_data_x, test_data_x, train_data_y, test_data_y \
= train_test_split(input_data_x, input_data_y, test_size=0.2, random_state=0)
# LinearRegressionクラスを利用するため、抜き出したtrain_data,test_dataの
# x座標・y座標を、2次元1列の配列とする縦ベクトルに変更
train_data_x = train_data_x.reshape(-1, 1)
train_data_y = train_data_y.reshape(-1, 1)
test_data_x = test_data_x.reshape(-1, 1)
test_data_y = test_data_y.reshape(-1, 1)
# train_dataの値から、回帰直線を算出
clf = linear_model.LinearRegression()
clf.fit(train_data_x, train_data_y)
# 算出した回帰直線のa,bの値
a = clf.coef_[0][0]
b = clf.intercept_[0]
print("*** a,bの値 ***")
print("a = " + str(a) + ", b = " + str(b))
print()
# 算出した回帰直線から、test_dataのx座標からy座標の値を算出し、
# 実際のテストデータの値と比較
predict_data_y = clf.predict(test_data_x)
print("*** test_data_xの値 ***")
print(test_data_x.reshape(1, -1))
print("*** test_dataのx座標から算出したy座標の値 ***")
print(predict_data_y.reshape(1, -1))
print("*** test_data_yの値 ***")
print(test_data_y.reshape(1, -1))
なお、作成された回帰直線が正しく機能するのは、訓練用データの範囲内(=内挿)の場合のみで、訓練用データの範囲外(=外挿)の場合は、正しく機能しないことがあるので、注意する必要がある。
詳細は、例えば以下のサイトを参照のこと。
https://atmarkit.itmedia.co.jp/ait/articles/2008/26/news017.html
要点まとめ
- scikit-learnには、入力データを、訓練用データとテストデータに分割できるtrain_test_splitメソッドがある。





