ニューラルネットワークでKerasに含まれるMNIST(手描き数字)のデータを分類してみた
以下の記事で、Kerasに含まれるMNIST(手描き数字)のデータを確認している。

Kerasに含まれるMNIST(手描き数字)のデータを取得してみたこれから、ニューラルネットワークで手書き数字を分類することを考えていくが、その際に、Kerasに含まれるMNIST(手描き数字)のデータ...
今回は、Kerasに含まれるMNIST(手描き数字)のデータを利用して、手書き数字の分類を行ってみたので、そのサンプルプログラムを共有する。
今回作成したニューラルネットワークの構成は、以下の通り。
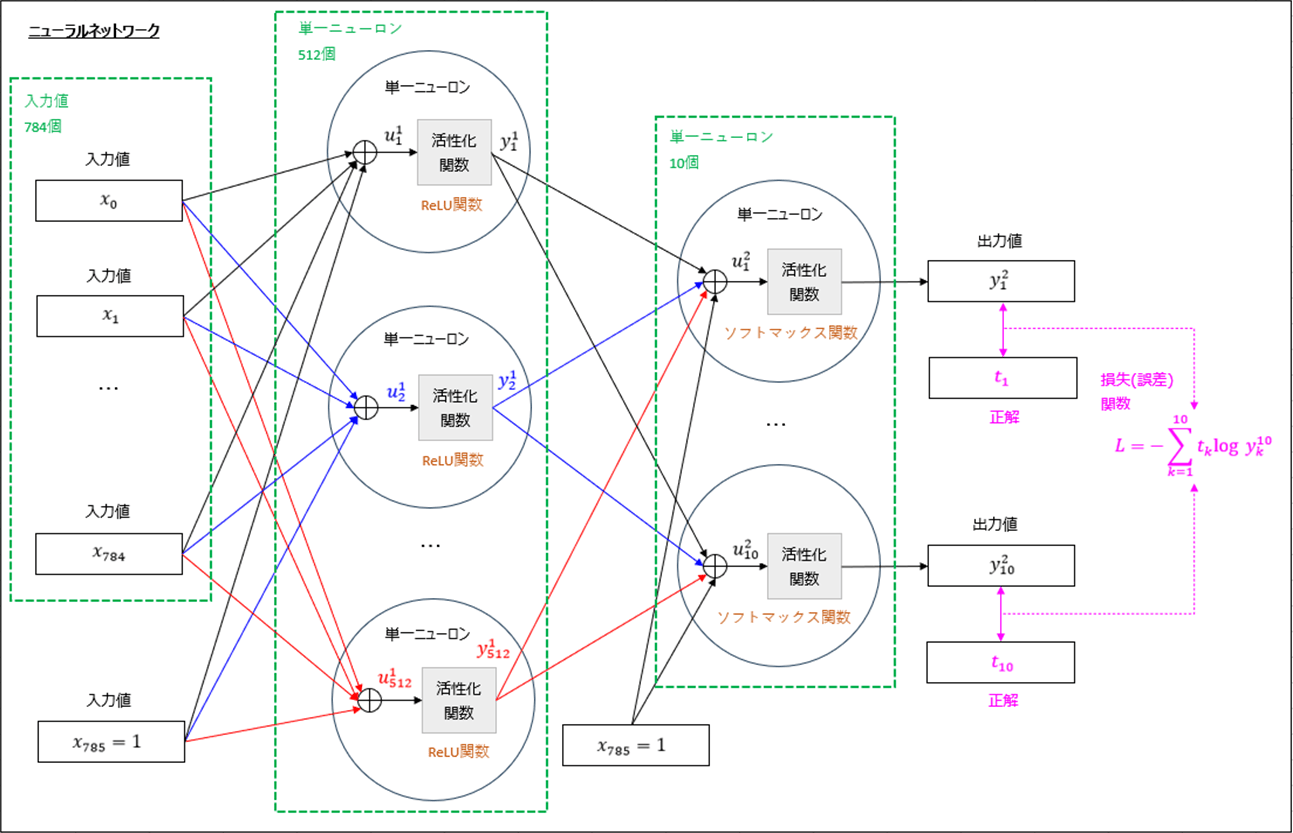
上記ニューラルネットワークをKerasで構成し、手書き数字の分類を行うサンプルプログラムの内容は以下の通りで、テストデータの約\(97.5\)%において、手書き数字の分類が正常に行えていることが確認できる。
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Activation, Dense
import numpy as np
### 前処理
# Kerasに含まれているMNIST(手描き数字)のデータを読み込む
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 訓練データ・テストデータの入力データを0~1の範囲に限定
x_train = x_train/255.0
x_test = x_test/255.0
# 訓練データ・テストデータの入力データを1次元配列に変換
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
# 訓練データ・テストデータの正解データをOne-Hotエンコーディング変換
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
### モデルの構築
# Kerasでニューラルネットワークのモデルを作成する
model = Sequential()
# 入力値x_1, x_2を取り込む単一ニューロン(512個)を作成し、
# 活性化関数にReLU関数を指定
model.add(Dense(512))
model.add(Activation('relu'))
# 出力値yを出力する単一ニューロン(10個)を作成し、
# 活性化関数にソフトマックス関数を指定
model.add(Dense(10))
model.add(Activation('softmax'))
# モデルをコンパイル
# その際、損失(誤差)関数(loss)、最適化関数(optimizer)、評価関数(metrics)を指定
#
# 損失(誤差)関数(loss)に多クラス分類(CategoricalCrossentropy)を指定
# 最適化関数(optimizer)にadam(SGDの改良版)を指定
# 評価関数(metrics)に正解率(accuracy)を指定
#
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 読み込んだ訓練データを用いて、モデルの学習を行う
# 繰り返し回数はepochsで指定
model.fit(x_train, y_train, epochs=10)
print()
### モデルの検証
# テストデータの正答率を算出
print("*** テストデータの正答率を算出 ***")
model.evaluate(x_test, y_test)
print()
# テスト用データを用いた検証結果(先頭5件)を計算
print("*** テスト用データの検証結果(先頭5件) ***")
np.set_printoptions(precision=2, suppress=True)
print(model.predict(x_test[0:5]))
print()
print("*** y_test(テスト用データ(正解データ))の先頭5件の変換後データ ***")
print(y_test[0:5])

「FlexClip」はテンプレートとして利用できる動画・画像・音楽などが充実した動画編集ツールだったテンプレートとして利用できるテキスト・動画・画像・音楽など(いずれも著作権フリー)が充実している動画編集ツールの一つに、「FlexCli...
その他、ニューラルネットワークには、「過学習」「バッチサイズ」「ドロップアウト」という重要な概念がある。詳細は、それぞれ以下のサイトを参照のこと。
●過学習
https://data-viz-lab.com/overfitting
●バッチサイズ
https://qiita.com/kenta1984/items/bad75a37d552510e4682
●ドロップアウト
https://zero2one.jp/ai-word/dropout/
先ほどのサンプルプログラムに、バッチサイズ・ドロップアウトの設定を加えた結果は、以下の通り。
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Activation, Dense, Dropout
import numpy as np
### 前処理
# Kerasに含まれているMNIST(手描き数字)のデータを読み込む
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 訓練データ・テストデータの入力データを0~1の範囲に限定
x_train = x_train/255.0
x_test = x_test/255.0
# 訓練データ・テストデータの入力データを1次元配列に変換
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
# 訓練データ・テストデータの正解データをOne-Hotエンコーディング変換
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
### モデルの構築
# Kerasでニューラルネットワークのモデルを作成する
model = Sequential()
# 入力値x_1, x_2を取り込む単一ニューロン(512個)を作成し、
# 活性化関数にReLU関数を指定
model.add(Dense(512))
model.add(Activation('relu'))
# データの偏りを減らすため、20%のデータを捨てる(Dropout)
model.add(Dropout(0.2))
# 出力値yを出力する単一ニューロン(10個)を作成し、
# 活性化関数にソフトマックス関数を指定
model.add(Dense(10))
model.add(Activation('softmax'))
# モデルをコンパイル
# その際、損失(誤差)関数(loss)、最適化関数(optimizer)、評価関数(metrics)を指定
#
# 損失(誤差)関数(loss)に多クラス分類(CategoricalCrossentropy)を指定
# 最適化関数(optimizer)にadam(SGDの改良版)を指定
# 評価関数(metrics)に正解率(accuracy)を指定
#
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 読み込んだ訓練データを用いて、モデルの学習を行う
# バッチサイズはbatch_sizeで指定
# 繰り返し回数はepochsで指定
model.fit(x_train, y_train, batch_size=100, epochs=10)
print()
### モデルの検証
# テストデータの正答率を算出
print("*** テストデータの正答率を算出 ***")
model.evaluate(x_test, y_test)
print()
# テスト用データを用いた検証結果(先頭5件)を計算
print("*** テスト用データの検証結果(先頭5件) ***")
np.set_printoptions(precision=2, suppress=True)
print(model.predict(x_test[0:5]))
print()
print("*** y_test(テスト用データ(正解データ))の先頭5件の変換後データ ***")
print(y_test[0:5])
要点まとめ
- Kerasを用いたニューラルネットワークを構築することで、MNIST(手描き数字)のデータを分類できる。
- ディープラーニングの重要な概念に、過学習・バッチサイズ・ドロップアウトがある。





