VSCodeでGitHub Copilot Chatを使ってみた
GitHub Copilotは、OpenAIの技術を活用したAIコード補完・支援ツールで、開発エディタ(IDE)内で、ソースコード・テストコードの作成やpydocコメントの追加、コード説明文の表示等を行える。
今回は、VSCode上でGitHub Copilot Chatを使ってみたので、その実施例を共有する。
前提条件
下記記事の「GitHub Copilot Proの購入」の内容が完了していること。

また、下記記事の手順に従って、VSCodeのインストールとVSCodeの日本語化が完了していること。

やってみたこと
- VSCodeでGitHub Copilot Chatを利用するための設定
- GitHub Copilot Chatによるソースコード作成
- GitHub Copilot Chatによるpydocコメントの作成
- GitHub Copilot Chatによるソースコード説明文とテストコードの作成
VSCodeでGitHub Copilot Chatを利用するための設定
VSCodeでGitHub Copilot Chatを利用するには、拡張機能で「GitHub Copilot Chat」をインストール後、GitHubにサインインする。その手順は、以下の通り。
1) VSCodeの画面で、「拡張機能」ボタンを押下する。
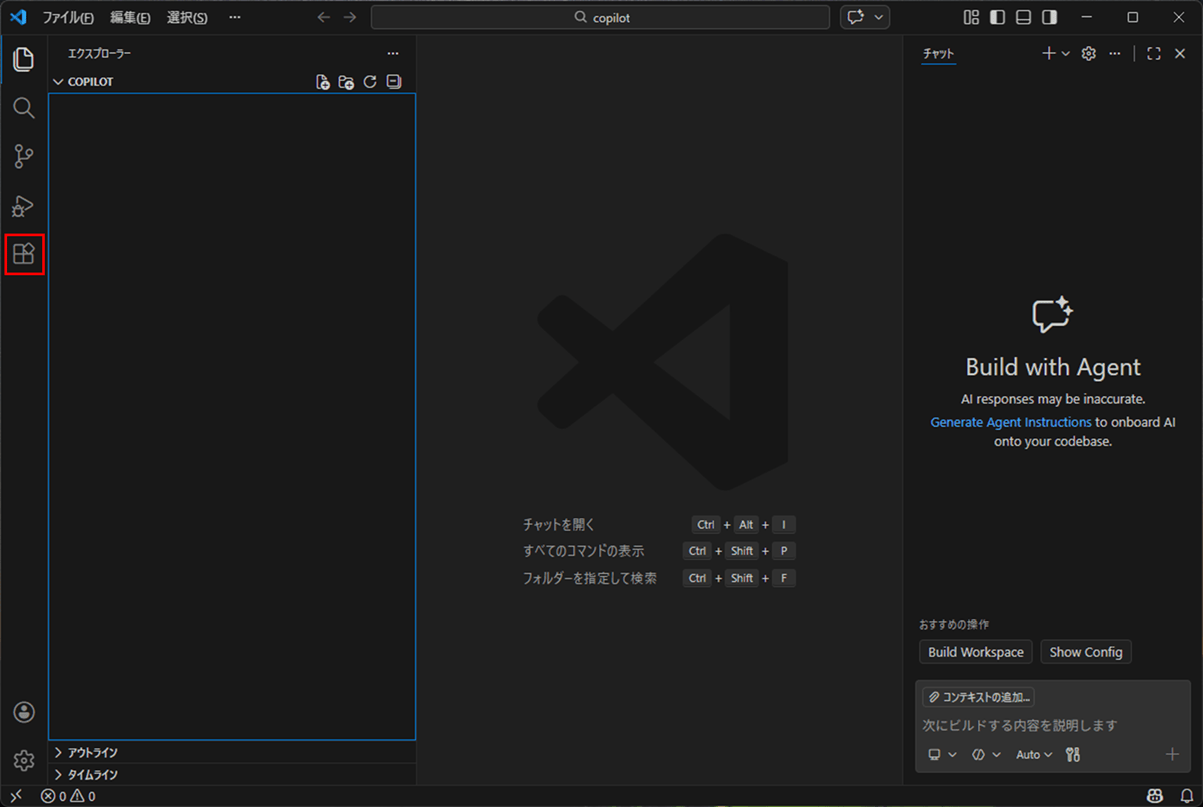
2)「GitHub Copilot Chat」を探し、「インストール」ボタンを押下する。
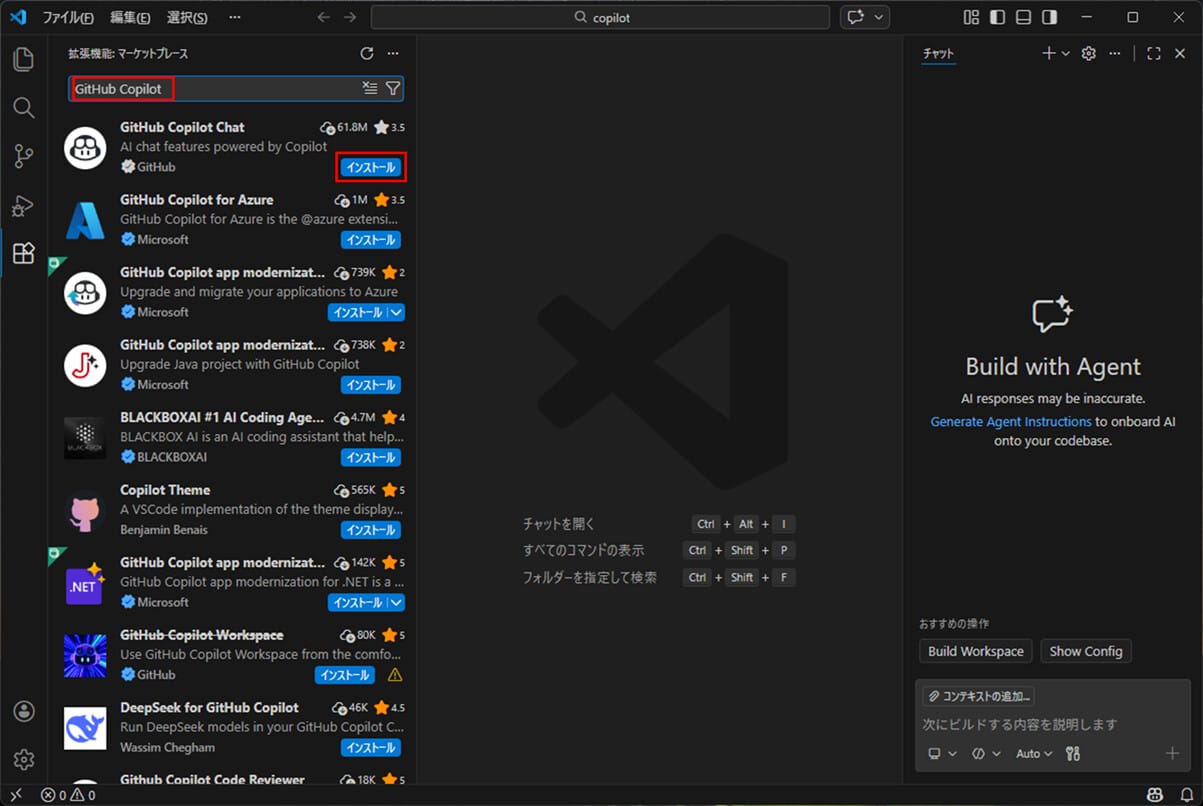
3) インストールが完了すると、下記画面が表示されるため、VSCodeを再起動する。
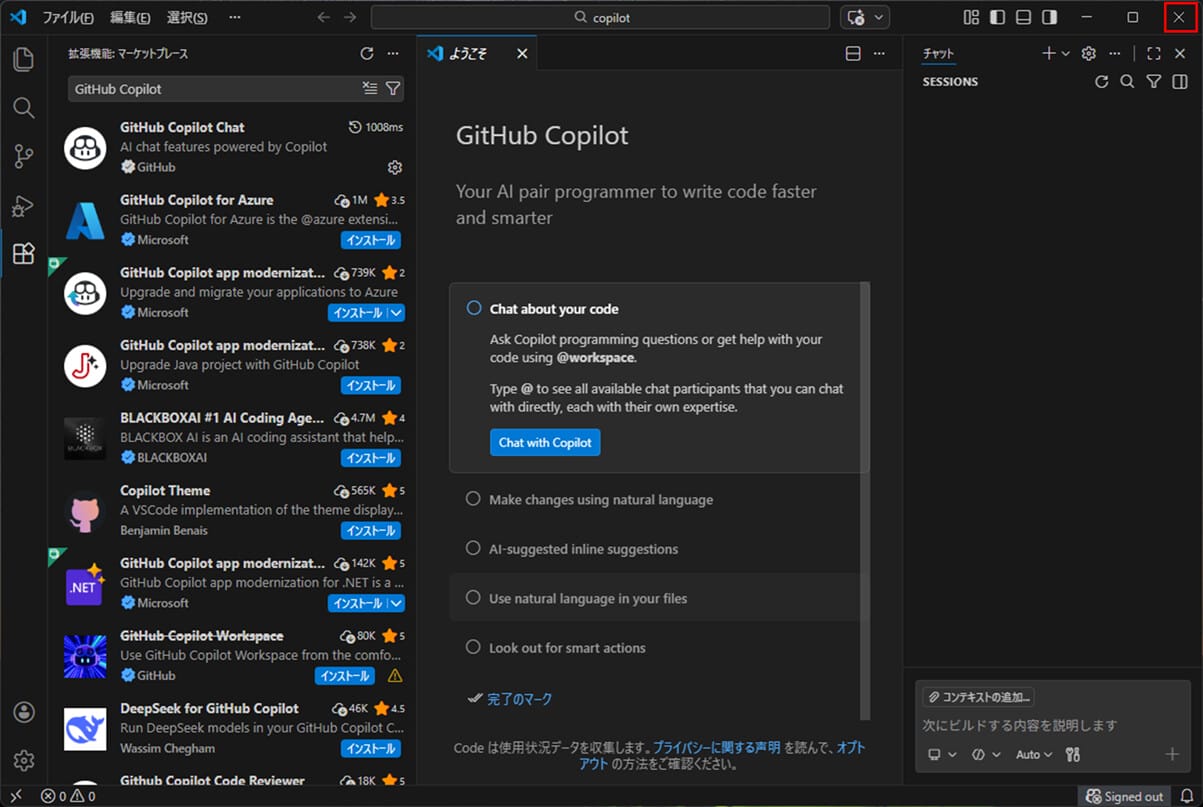
4) VSCodeを再起動すると、以下のように、GitHub Copilotのようこそ画面が日本語で表示されることが確認できる。
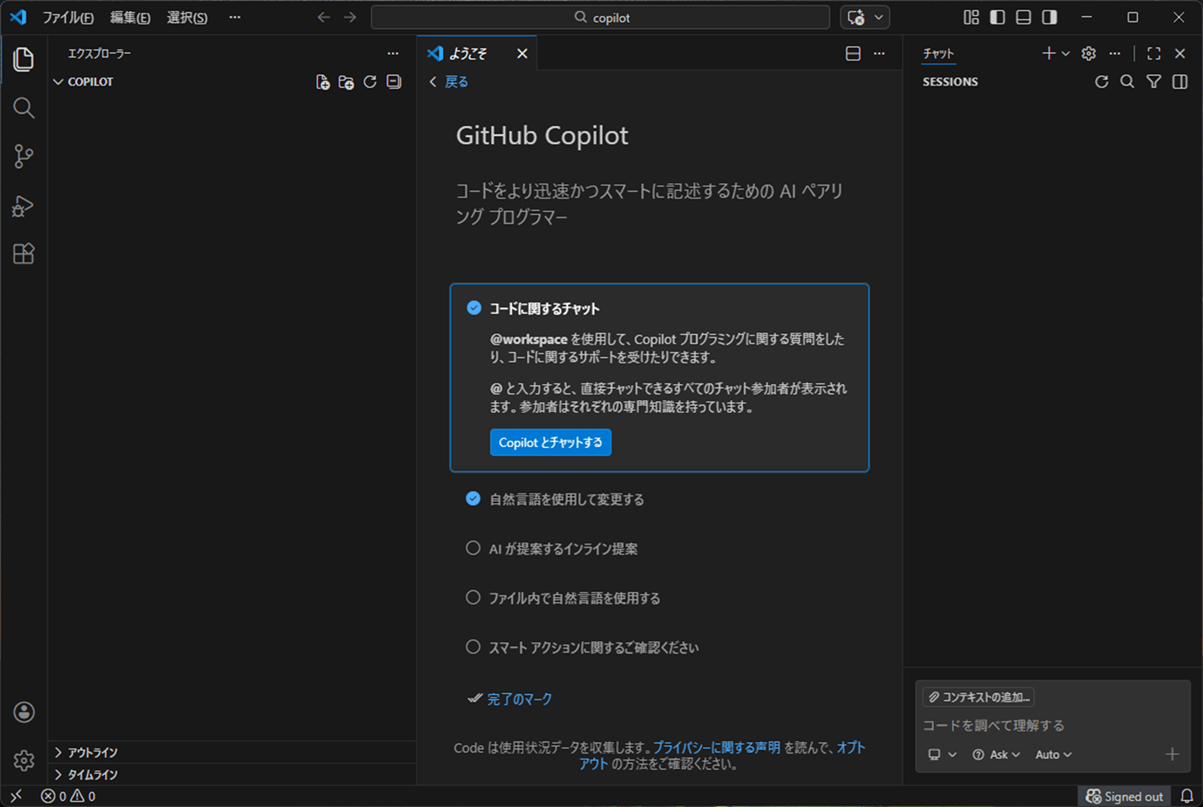
5) 右下の「Signed out」ボタン押下後、「Sign in to use AI Features」ボタンを押下する。
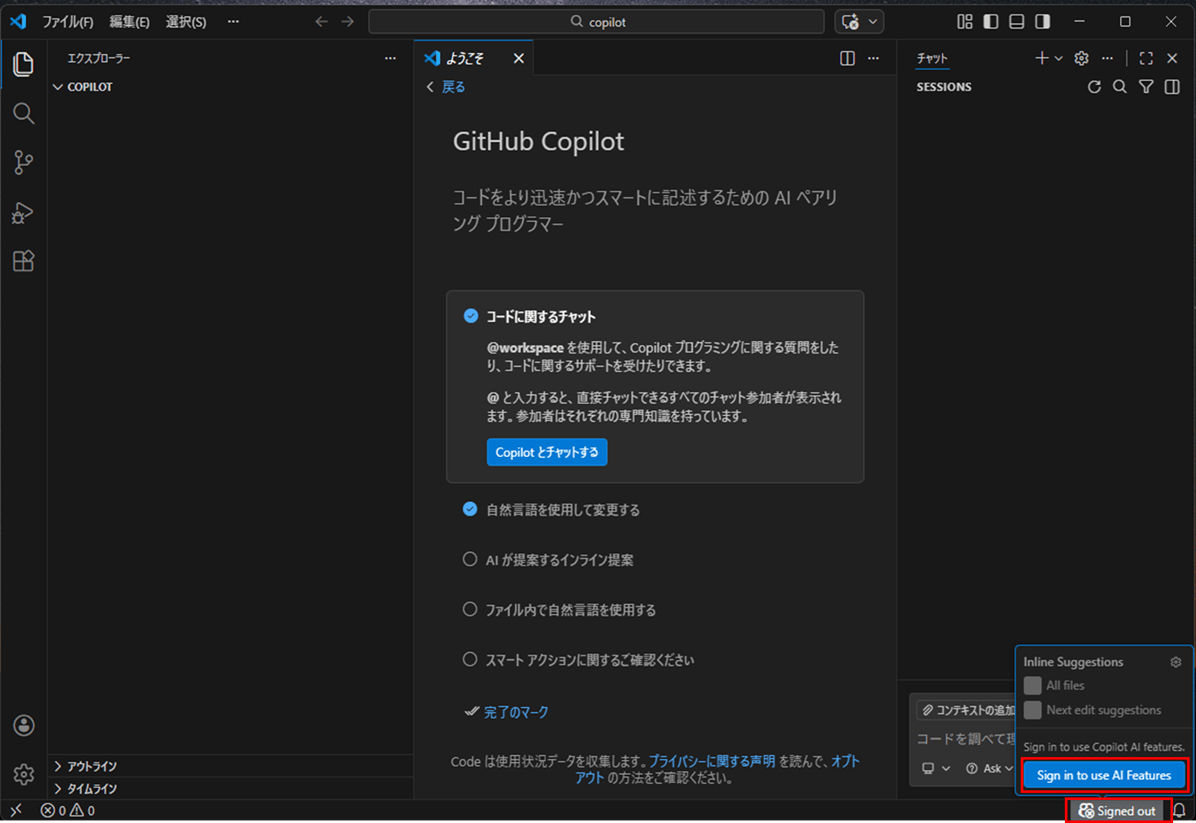
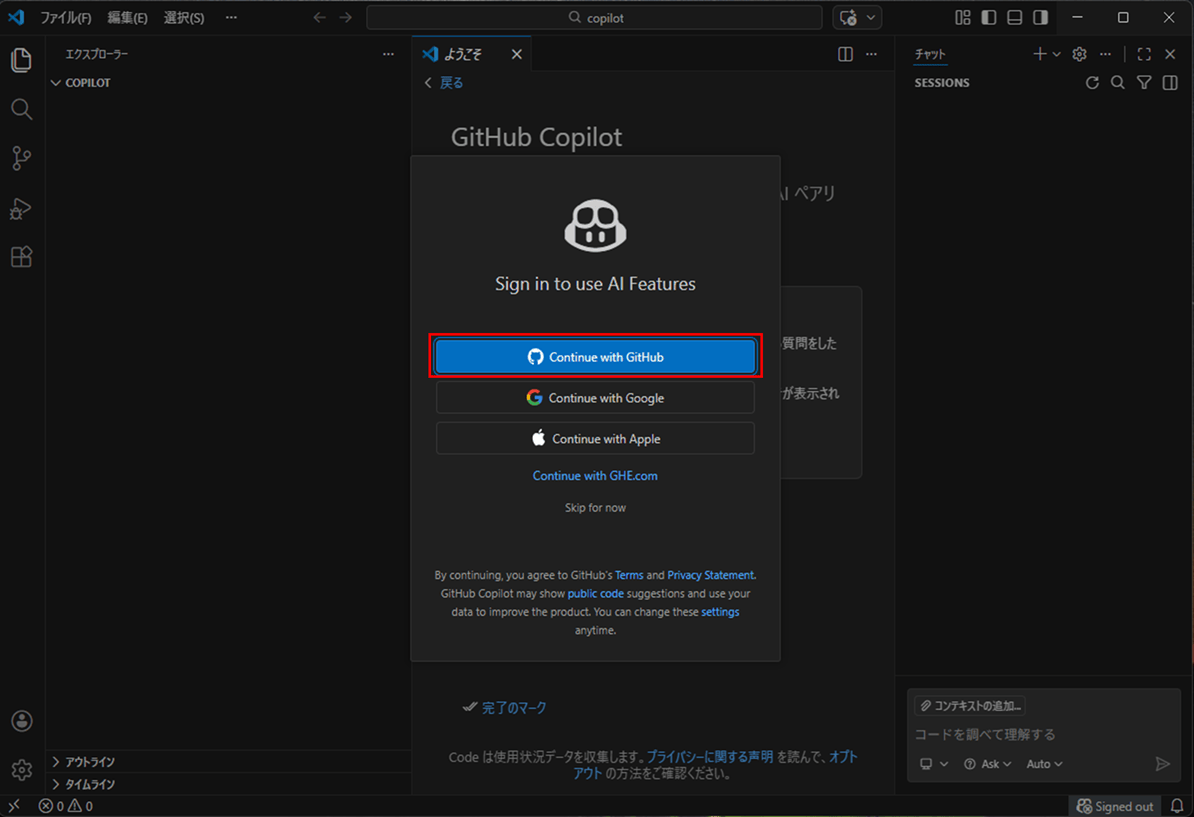
6)「Continue with GitHub」ボタンを押下し、GitHub CopilotをVSCodeで利用できる設定を追加していく。
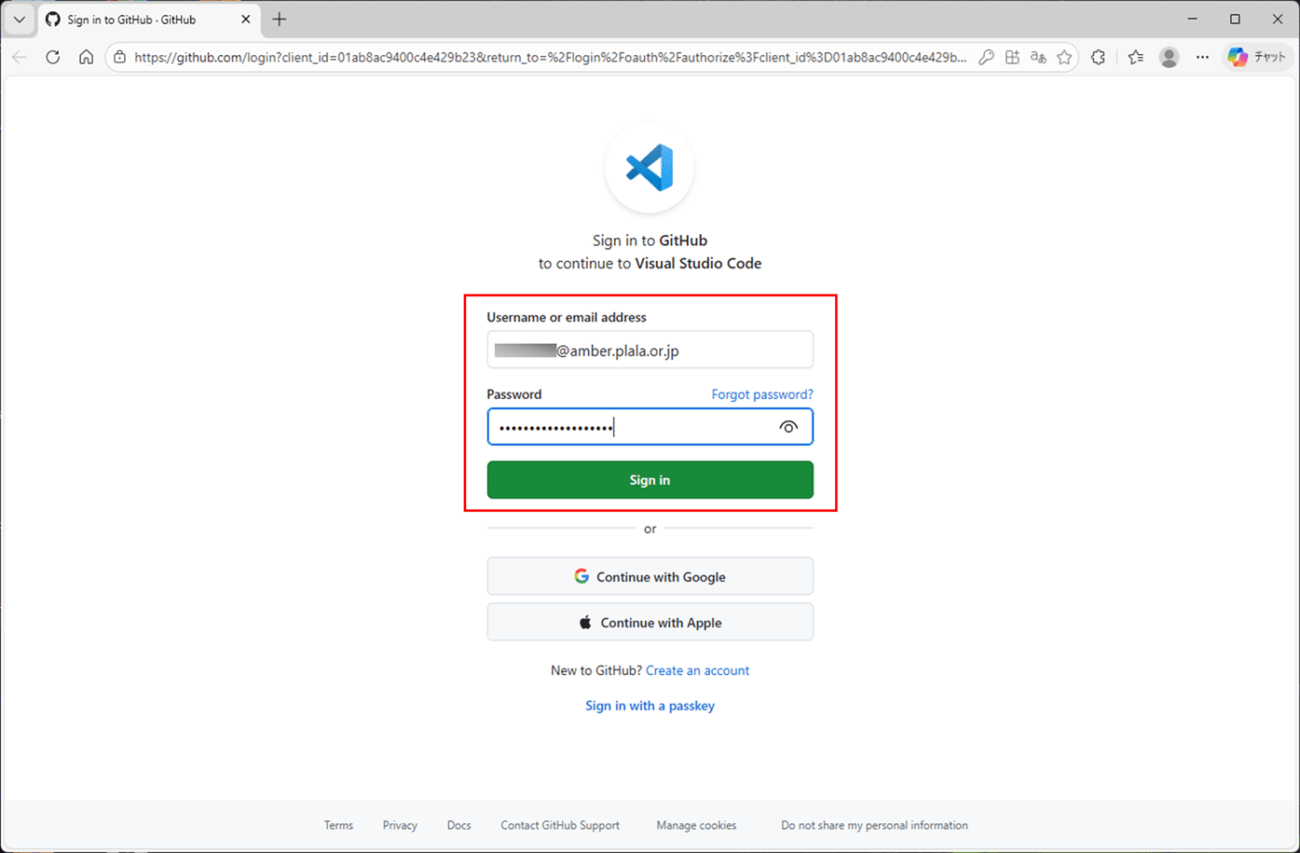
7) ブラウザ上に以下の画面が起動するため、ユーザー名・パスワードを指定後、「Sign in」ボタンを押下する。
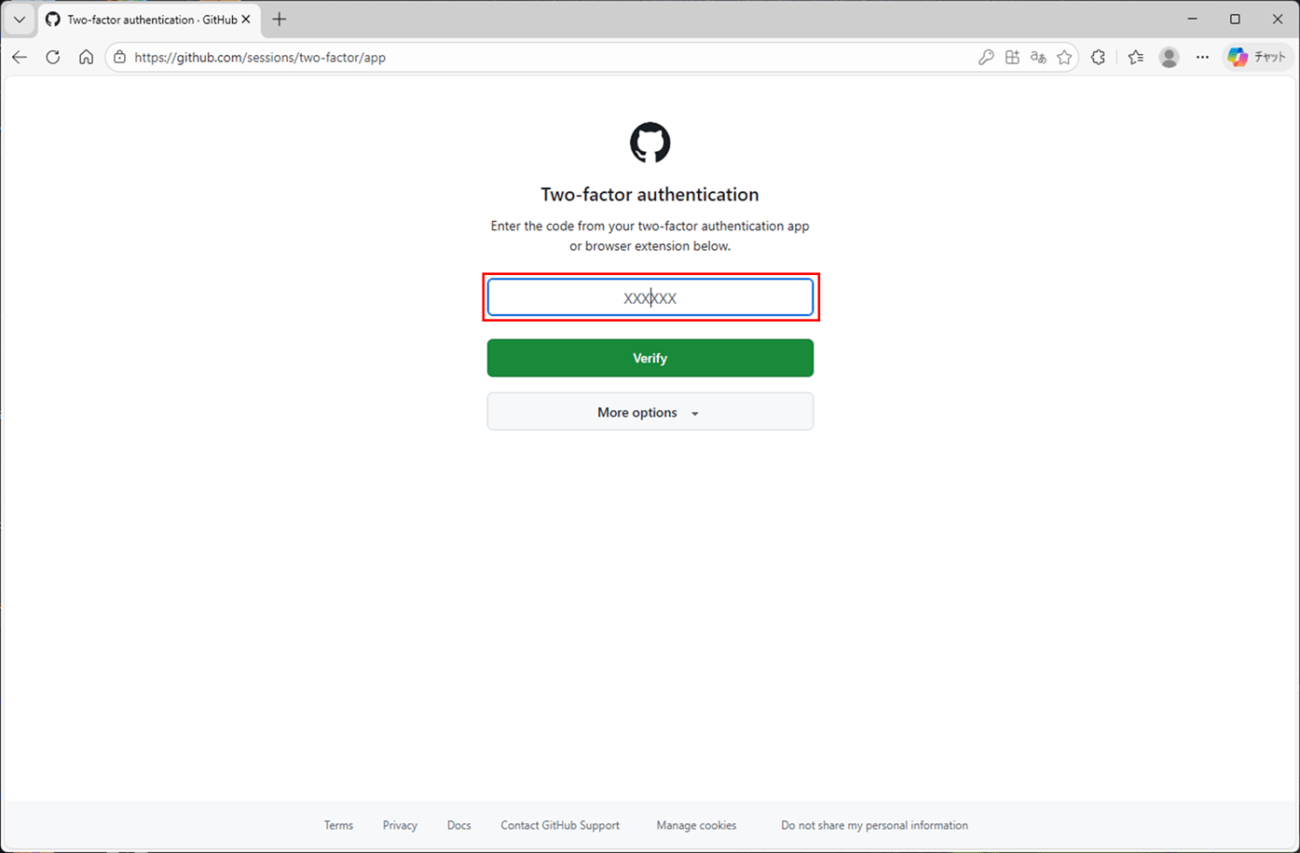
8) Authenticatorによる2段階認証を設定しているため、以下の画面が表示される。ここで、Authenticatorで表示される6桁の数値を指定すると、ログインできる。
9) そのまま、「Continue」ボタンを押下する。
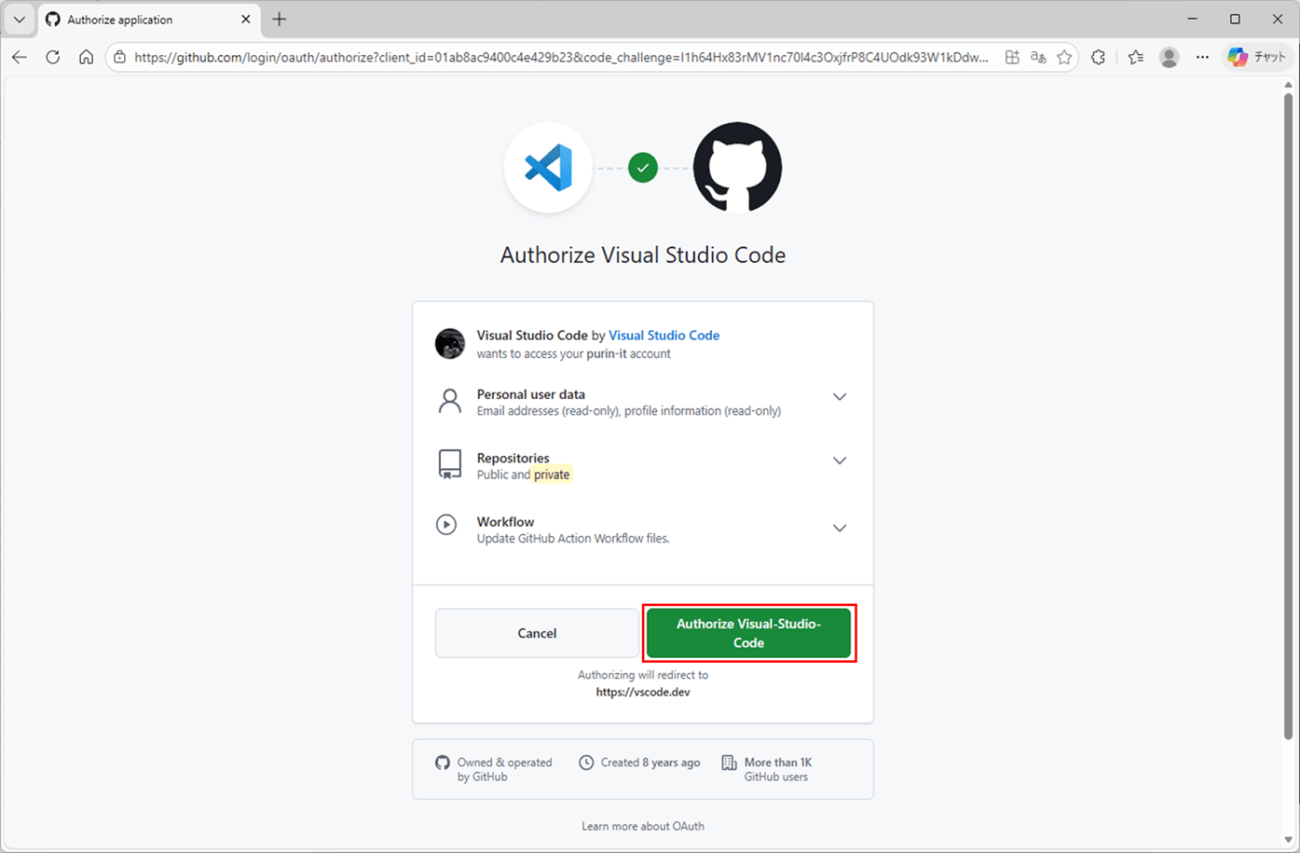
10) そのまま、「Authorize Visual-Studio-Code」ボタンを押下する。
11) この画面に遷移すると、VSCode上でCopilot Chatを利用できるようになる。
このとき、Visual Studio Codeの右下の「Signed out」ボタンが表示されず、Copilot Chatが利用可能になっている。
なお、拡張機能には、以下のように、GitHub Copilot Chatに加え、Pythonもインストール済であるとする。

GitHub Copilot Chatによるソースコード作成
GitHub Copilot Chatにソースコードを作成してもらうには、GitHub Copilot Chatのチャット欄で依頼すればよい。例えば、CSVファイルを読み込み、文字コードを判定する関数を自動生成させる実施例は、以下の通り。
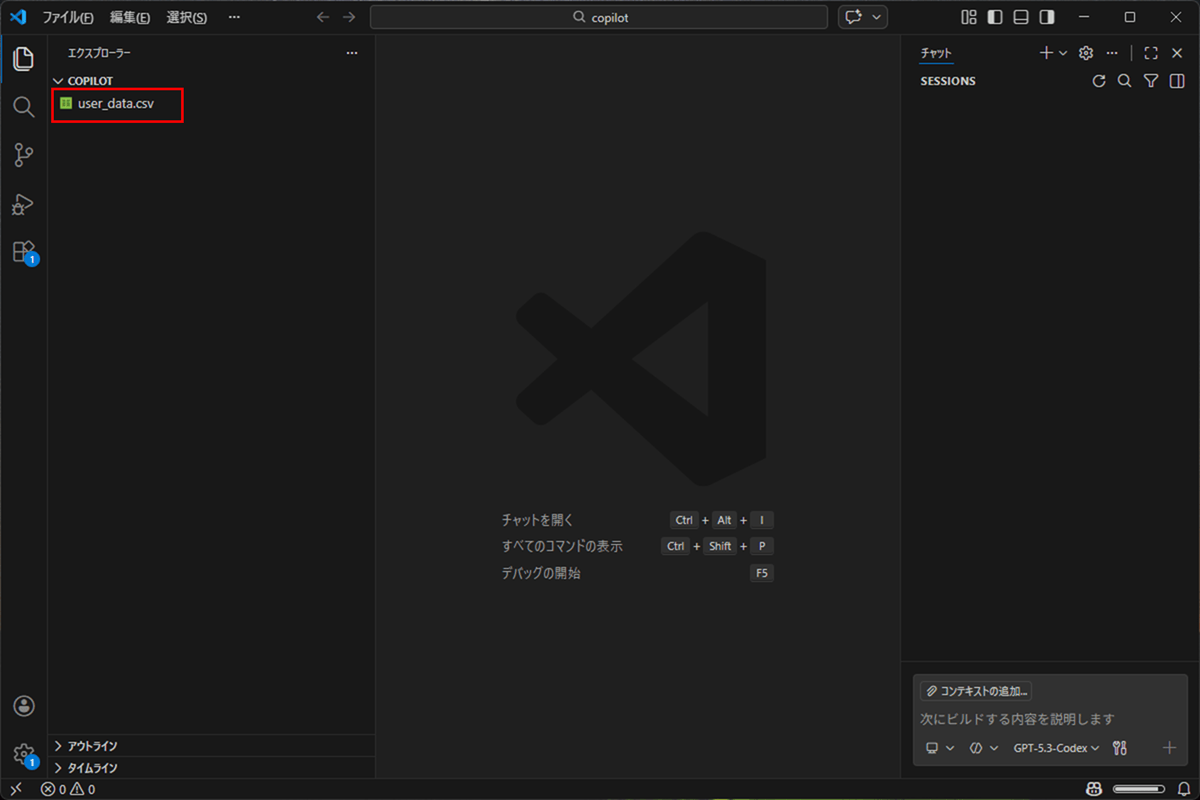
1) 以下のように、文字コード判定用に読み込むCSVファイル(user_data.csv)を置く。
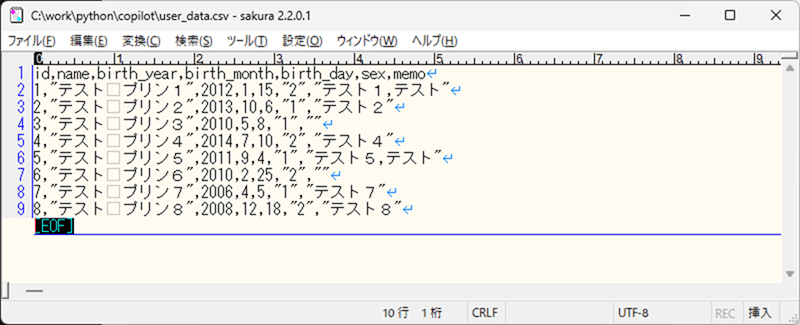
user_data.csvの中身は、以下の通り。
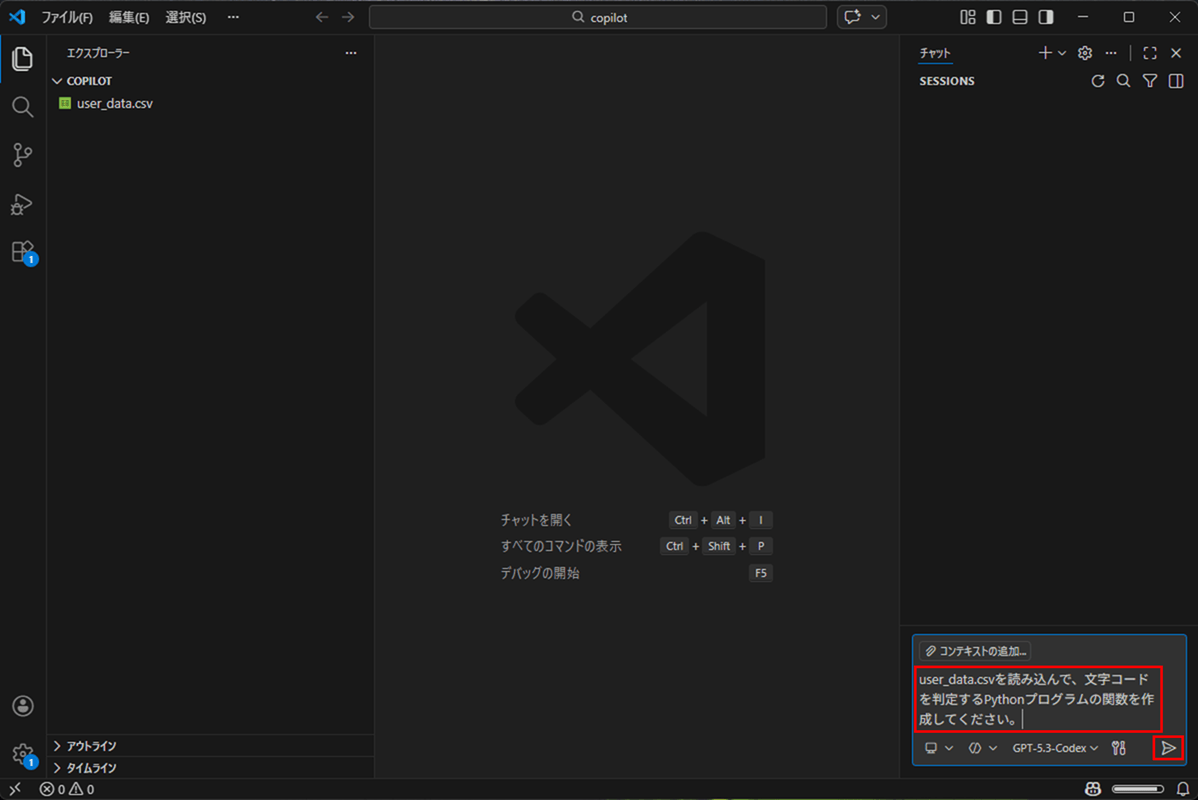
2) チャット欄に「user_data.csvを読み込んで、文字コードを判定するPythonプログラムの関数を作成してください。」と入力し、右下の三角ボタンを押下する。
3) 以下のように、Github Copilotが、依頼した内容のソースコード(csv_encoding_reader.py)を作成してくれたことが確認できる。
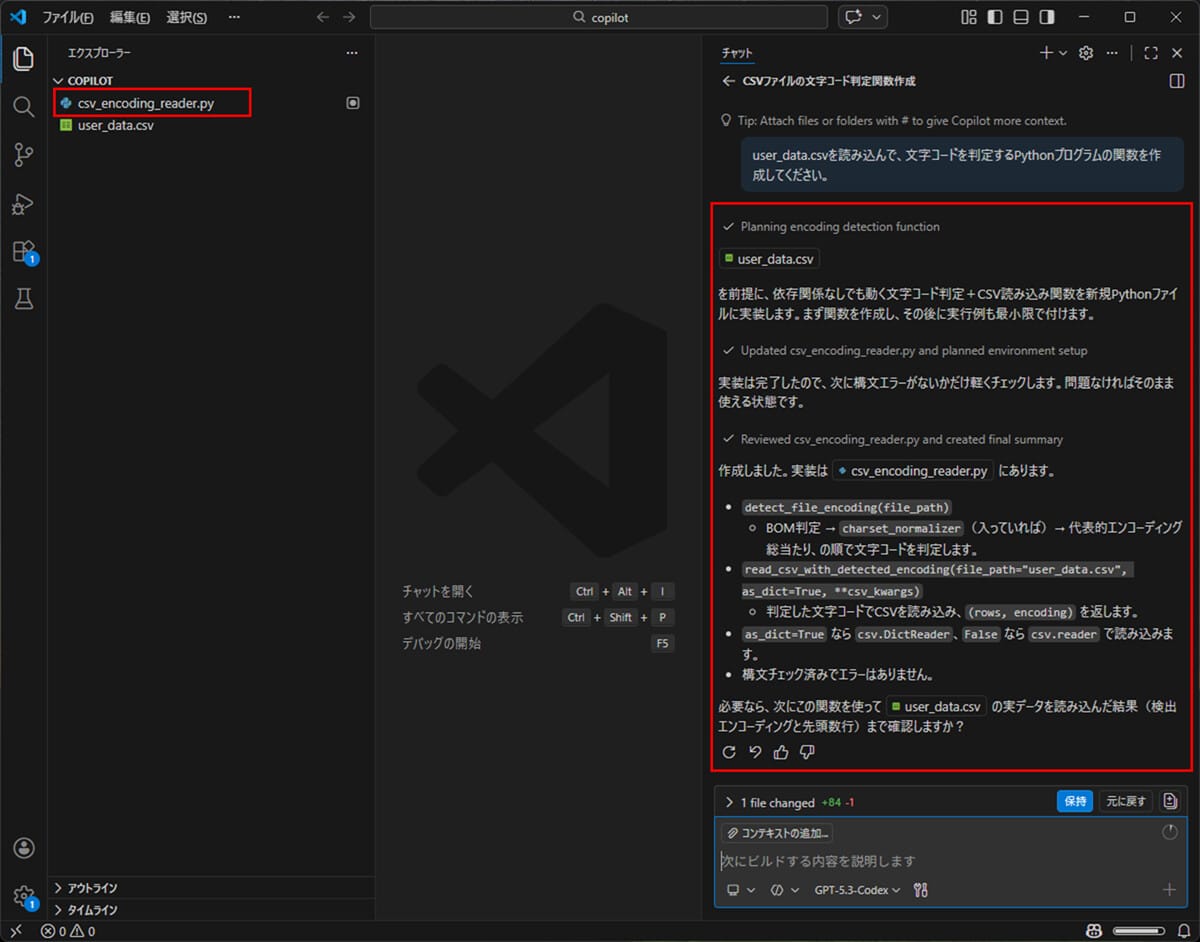
作成されたソースコード(csv_encoding_reader.py)の内容は、以下の通り。
from __future__ import annotations
import csv
from pathlib import Path
from typing import Any, Iterable
COMMON_ENCODINGS: list[str] = [
"utf-8-sig",
"utf-8",
"cp932",
"shift_jis",
"euc_jp",
"iso2022_jp",
"latin-1",
]
def _detect_by_bom(raw: bytes) -> str | None:
if raw.startswith(b"\xef\xbb\xbf"):
return "utf-8-sig"
if raw.startswith(b"\xff\xfe"):
return "utf-16-le"
if raw.startswith(b"\xfe\xff"):
return "utf-16-be"
if raw.startswith(b"\xff\xfe\x00\x00"):
return "utf-32-le"
if raw.startswith(b"\x00\x00\xfe\xff"):
return "utf-32-be"
return None
def detect_file_encoding(file_path: str | Path, sample_size: int = 100_000) -> str:
path = Path(file_path)
raw = path.read_bytes()[:sample_size]
if not raw:
return "utf-8"
by_bom = _detect_by_bom(raw)
if by_bom:
return by_bom
try:
from charset_normalizer import from_bytes
best = from_bytes(raw).best()
if best and best.encoding:
return best.encoding
except Exception:
pass
for encoding in COMMON_ENCODINGS:
try:
raw.decode(encoding)
return encoding
except UnicodeDecodeError:
continue
return "utf-8"
def read_csv_with_detected_encoding(
file_path: str | Path = "user_data.csv",
*,
as_dict: bool = True,
**csv_kwargs: Any,
) -> tuple[list[Any], str]:
path = Path(file_path)
encoding = detect_file_encoding(path)
with path.open("r", encoding=encoding, newline="") as file_obj:
if as_dict:
rows: Iterable[Any] = csv.DictReader(file_obj, **csv_kwargs)
else:
rows = csv.reader(file_obj, **csv_kwargs)
return list(rows), encoding
if __name__ == "__main__":
data, detected = read_csv_with_detected_encoding("user_data.csv")
print(f"Detected encoding: {detected}")
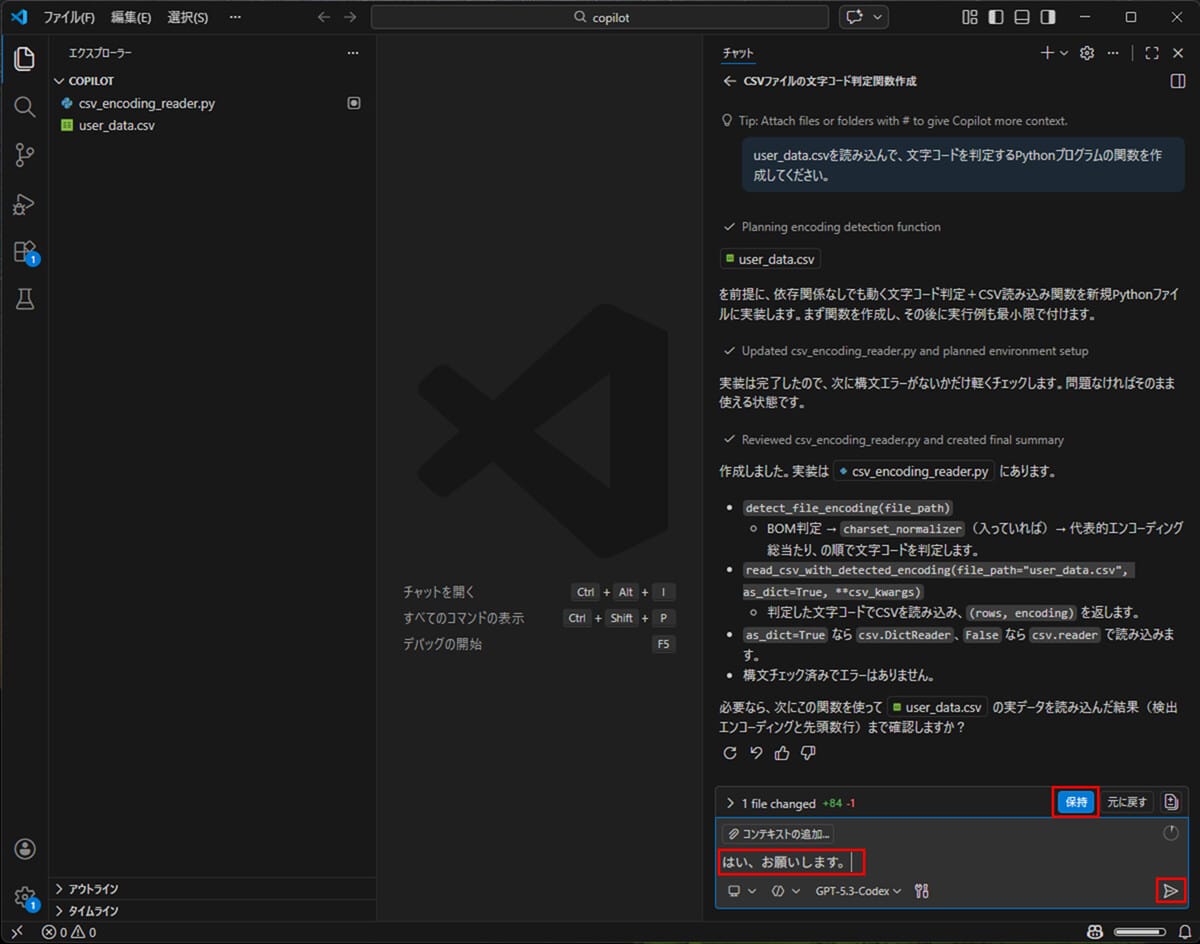
print(f"Loaded rows: {len(data)}")4)「保持」ボタンを押下し、GitHub Copilotとのやり取りを順次進めていく。
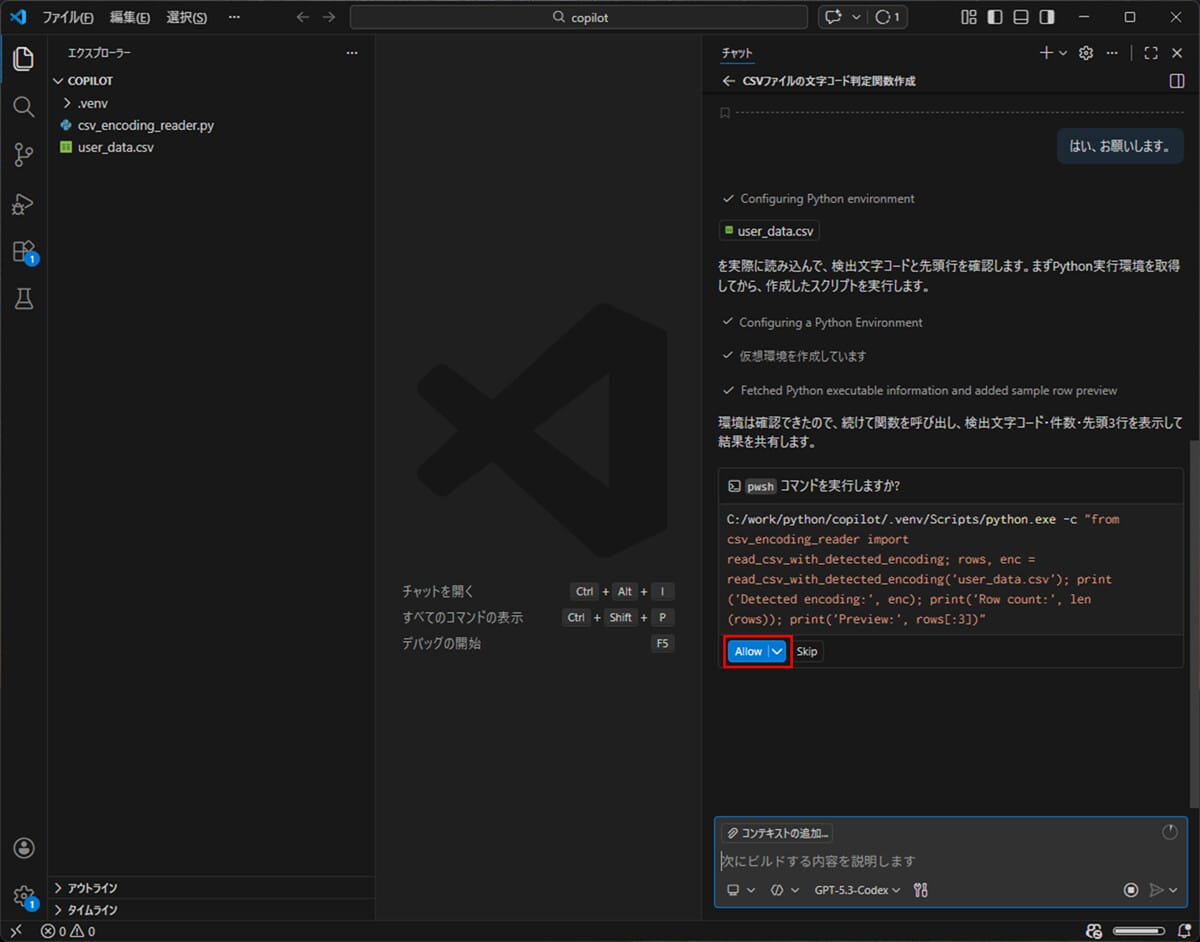
5) 以下のように、Github Copilotが作成したソースコード(csv_encoding_reader.py)を実行してくれたのが確認できる。
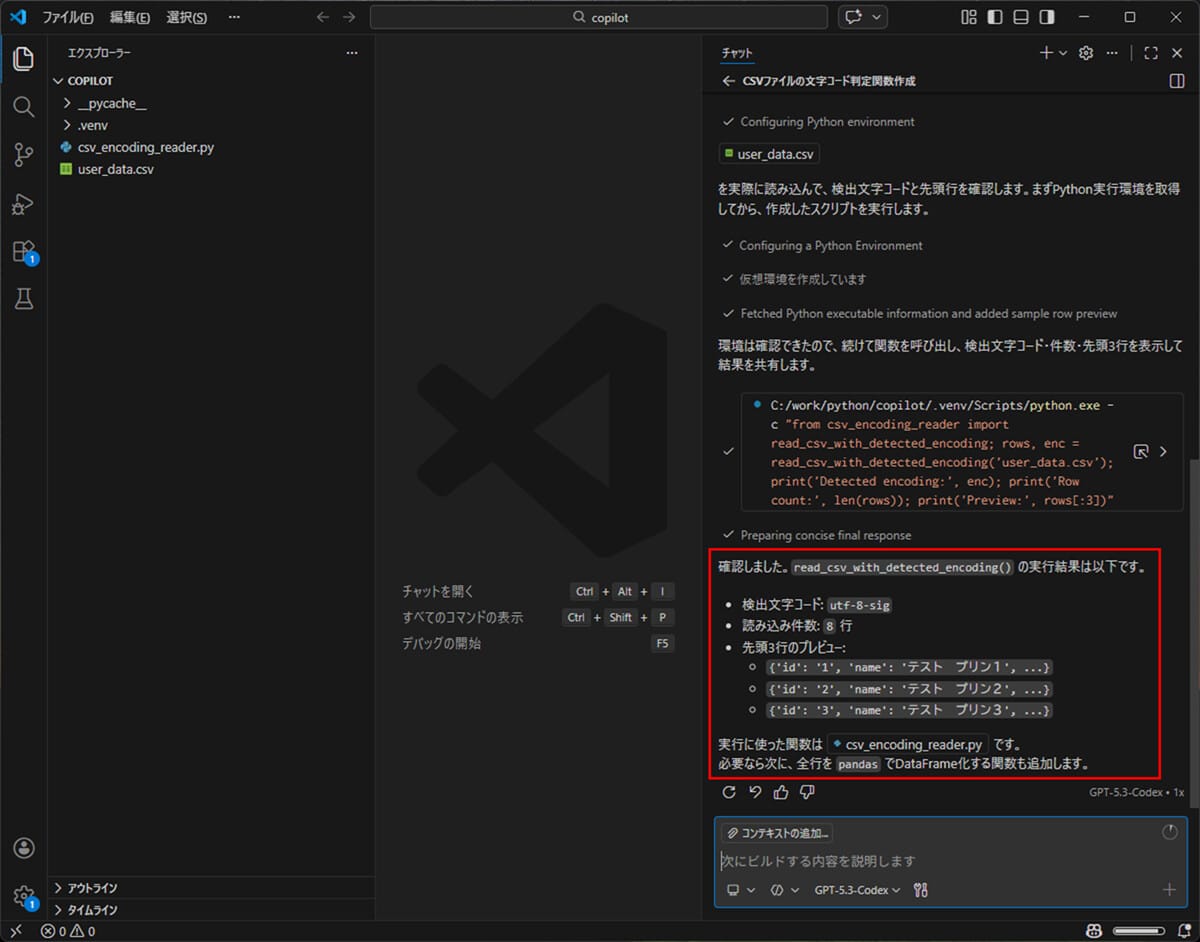
6) ここで、utf-8-sigの意味を確認するための質問すると、コーディング以外の質問に対しても、回答してもらえることが確認できる。
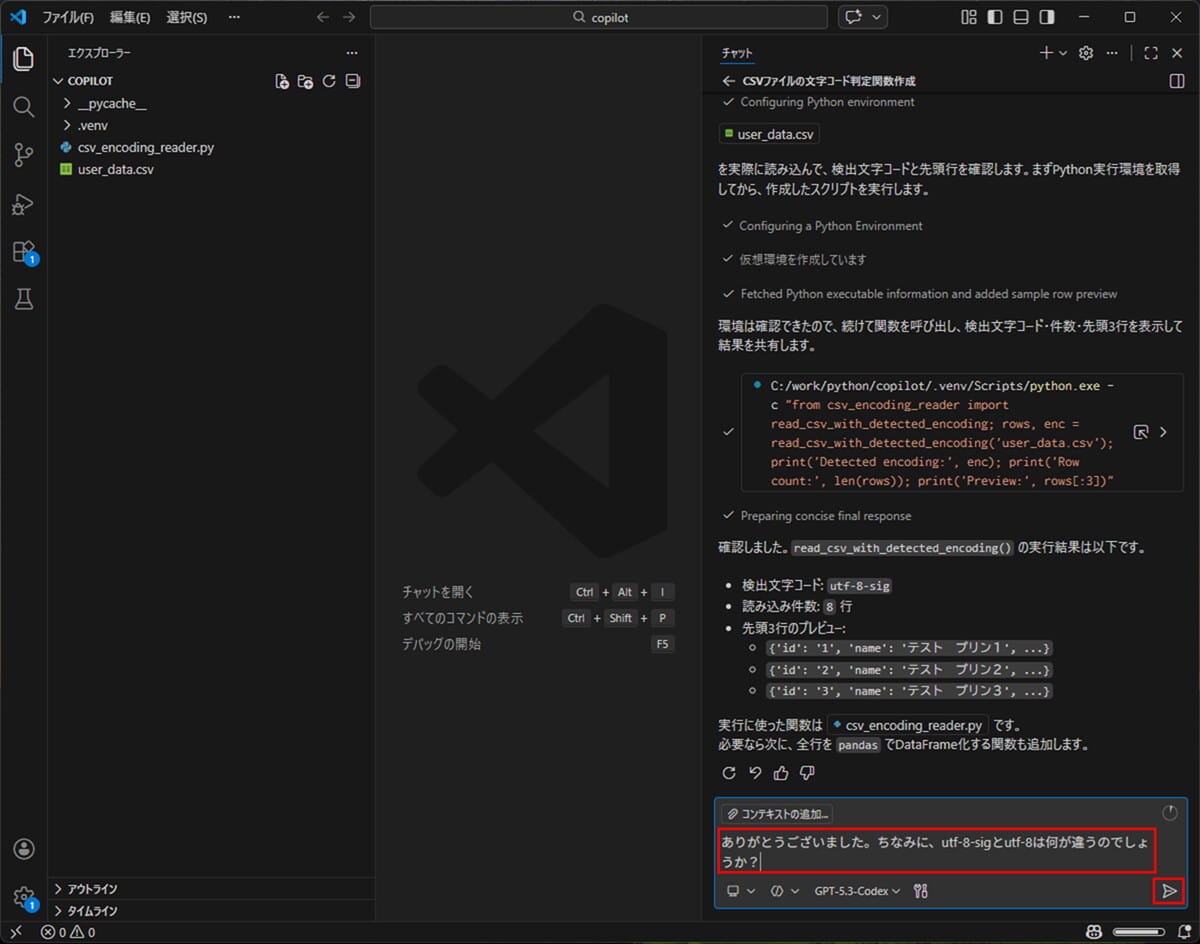
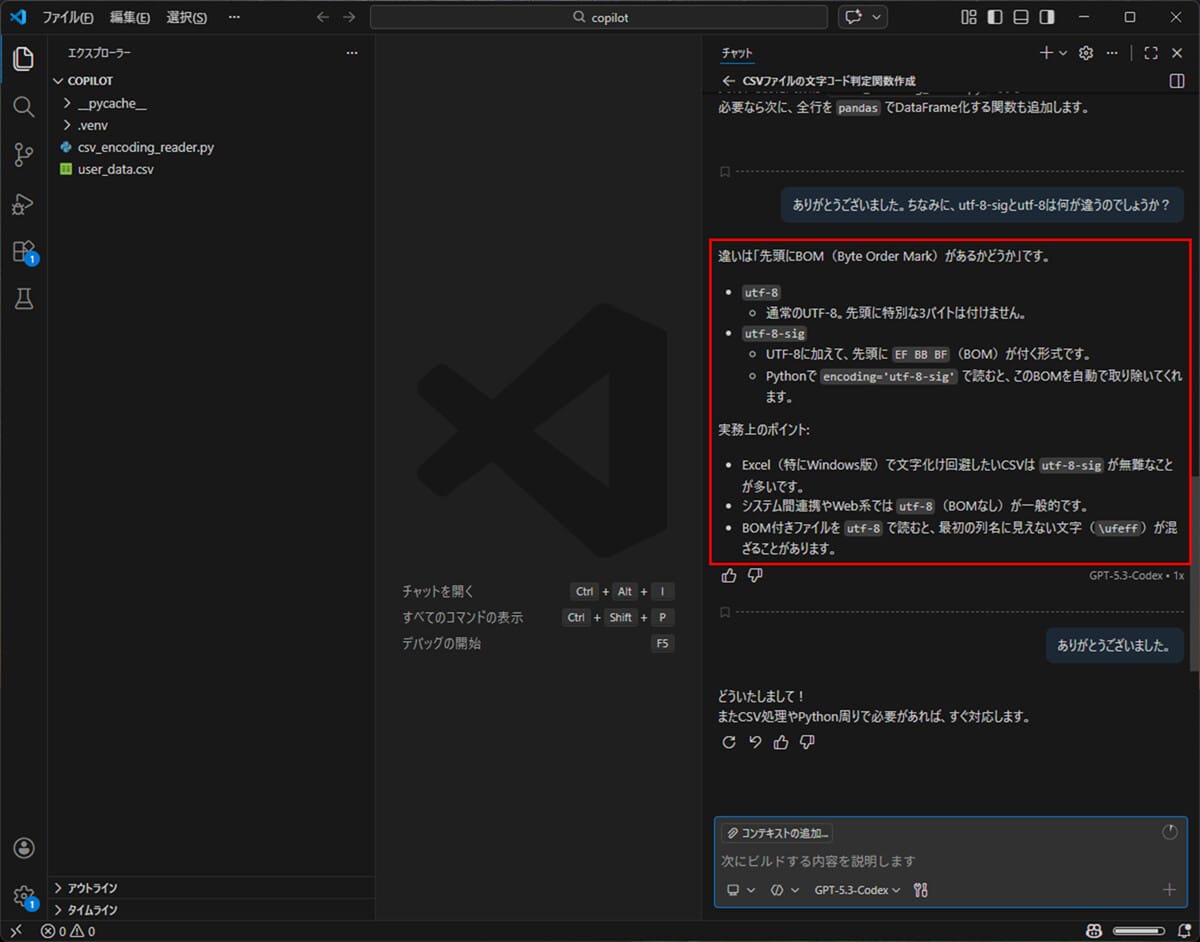

GitHub Copilot Chatによるpydocコメントの作成
Pythonの、モジュール・クラス・関数の定義直下に記述してその機能や使い方を説明する文書を、pydocコメント(Docstring)といい、GitHub Copilot Chatで指示を出すことで、pydocコメントを作成できる。その実施例は、以下の通り。
1) チャット欄に「/clear」を指定することで、これまでのチャットを削除する。
2) チャット欄に「csv_encoding_reader.pyにpydocコメントを追加してください。」と入力し、右下の三角ボタンを押下する。
3) 以下のように、指示通りにpydocコメントを追加してくれることが確認できる。
pydocコメントが追加されたソースコード(csv_encoding_reader.py)の内容は、以下の通り。
from __future__ import annotations
"""CSV ファイルの文字コード推定と読み込みを提供するユーティリティ。
主な用途:
- BOM から文字コードを判定
- 推定結果に基づいて CSV を安全に読み込み
- 必要に応じて `DictReader` / `reader` を切り替え
"""
import csv
from pathlib import Path
from typing import Any, Iterable
COMMON_ENCODINGS: list[str] = [
"utf-8-sig",
"utf-8",
"cp932",
"shift_jis",
"euc_jp",
"iso2022_jp",
"latin-1",
]
def _detect_by_bom(raw: bytes) -> str | None:
"""バイト列先頭の BOM から文字コードを推定する。
Parameters
----------
raw : bytes
文字コード判定対象の生バイト列。
Returns
-------
str | None
判定できた場合はエンコーディング名、判定できない場合は ``None``。
"""
if raw.startswith(b"\xef\xbb\xbf"):
return "utf-8-sig"
if raw.startswith(b"\xff\xfe"):
return "utf-16-le"
if raw.startswith(b"\xfe\xff"):
return "utf-16-be"
if raw.startswith(b"\xff\xfe\x00\x00"):
return "utf-32-le"
if raw.startswith(b"\x00\x00\xfe\xff"):
return "utf-32-be"
return None
def detect_file_encoding(file_path: str | Path, sample_size: int = 100_000) -> str:
"""CSV ファイルの文字コードを推定する。
判定順序は以下の通り:
1. BOM 判定
2. `charset_normalizer` が利用可能なら統計的推定
3. `COMMON_ENCODINGS` の順でデコード試行
4. すべて失敗した場合は ``utf-8`` を返却
Parameters
----------
file_path : str | Path
文字コードを推定する対象ファイルのパス。
sample_size : int, default 100_000
推定に使う先頭バイト数。
Returns
-------
str
推定した文字コード名。
"""
path = Path(file_path)
raw = path.read_bytes()[:sample_size]
if not raw:
return "utf-8"
by_bom = _detect_by_bom(raw)
if by_bom:
return by_bom
try:
from charset_normalizer import from_bytes
best = from_bytes(raw).best()
if best and best.encoding:
return best.encoding
except Exception:
pass
for encoding in COMMON_ENCODINGS:
try:
raw.decode(encoding)
return encoding
except UnicodeDecodeError:
continue
return "utf-8"
def read_csv_with_detected_encoding(
file_path: str | Path = "user_data.csv",
*,
as_dict: bool = True,
**csv_kwargs: Any,
) -> tuple[list[Any], str]:
"""推定した文字コードで CSV を読み込み、データと文字コードを返す。
Parameters
----------
file_path : str | Path, default "user_data.csv"
読み込む CSV ファイルのパス。
as_dict : bool, default True
``True`` の場合は `csv.DictReader` を使い、行を辞書として返す。
``False`` の場合は `csv.reader` を使い、行を配列として返す。
**csv_kwargs : Any
`csv.DictReader` / `csv.reader` にそのまま渡す追加引数。
Returns
-------
tuple[list[Any], str]
1 要素目は読み込んだ全行、2 要素目は使用した文字コード。
"""
path = Path(file_path)
encoding = detect_file_encoding(path)
with path.open("r", encoding=encoding, newline="") as file_obj:
if as_dict:
rows: Iterable[Any] = csv.DictReader(file_obj, **csv_kwargs)
else:
rows = csv.reader(file_obj, **csv_kwargs)
return list(rows), encoding
if __name__ == "__main__":
data, detected = read_csv_with_detected_encoding("user_data.csv")
print(f"Detected encoding: {detected}")
print(f"Loaded rows: {len(data)}")4)「保持」ボタンを押下し、GitHub Copilotとのやり取りを続ける。
GitHub Copilot Chatによるソースコード説明文とテストコードの作成
GitHub Copilot Chatを利用すると、ソースコード説明文の作成やテストコード作成も行える。その実施例は、以下の通り。
1) チャット欄に「/explain (@workspaceの方)」を指定し、右下の三角ボタンを押下する。
2) 説明文を表示するコード全体を選択する必要があっため、選択後、再度同じ操作を実施する。
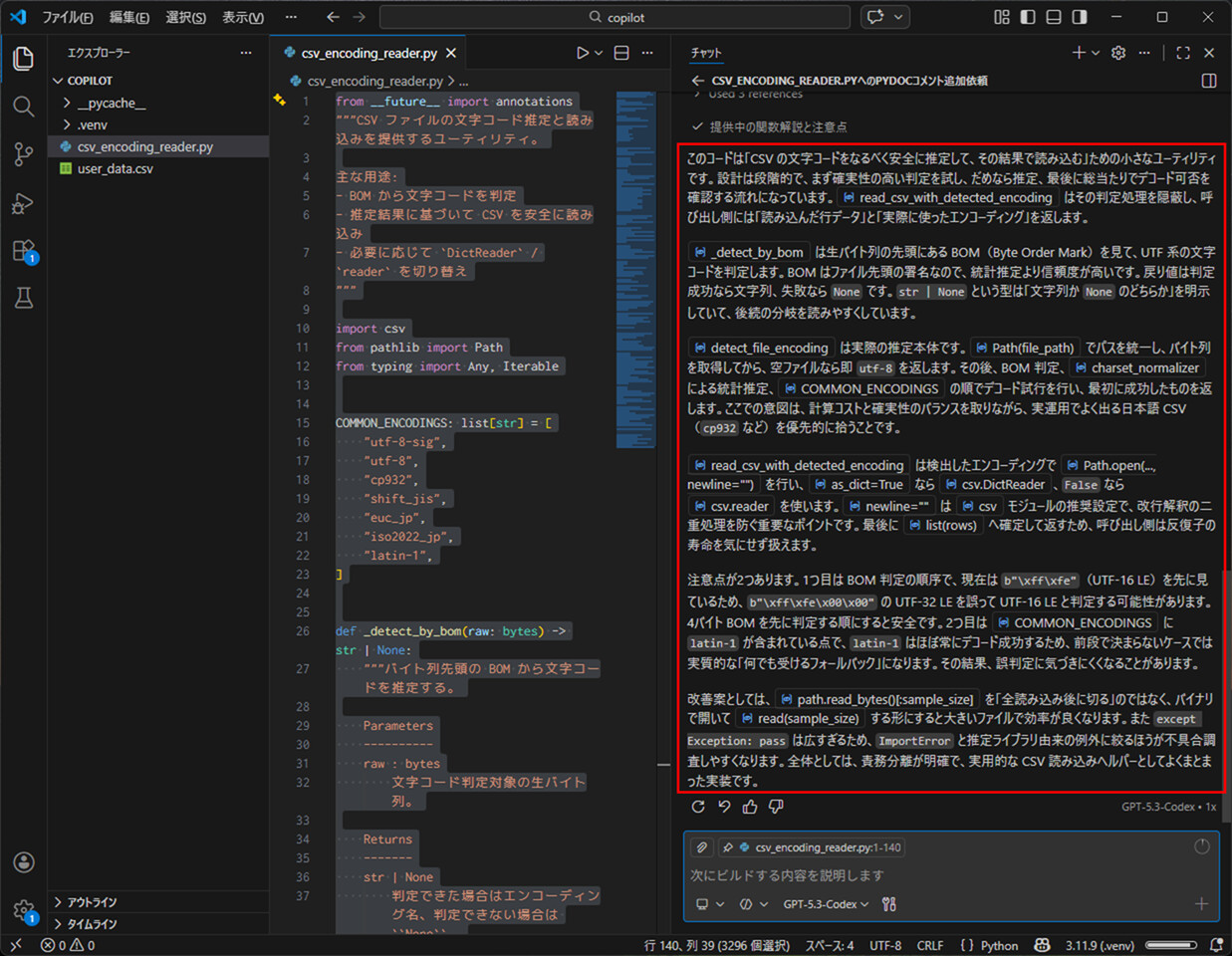
3) 以下のように、コードの内容について、丁寧に説明してくれることが確認できる。
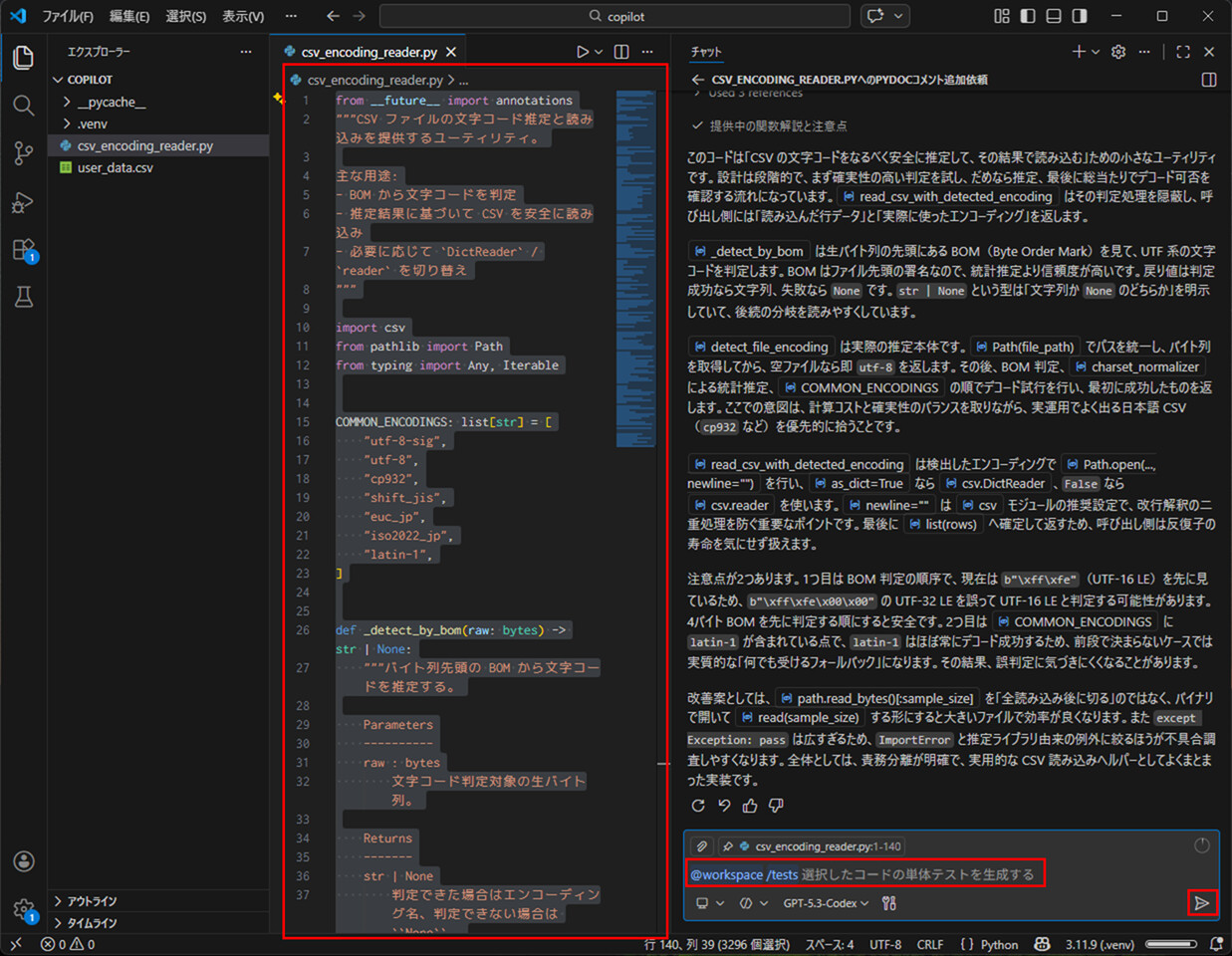
4) 似たような手順で、テストコードの作成も行える。コード全体を選択後、チャット欄に「/tests (@workspace)」を指定し、右下の三角ボタンを押下する。
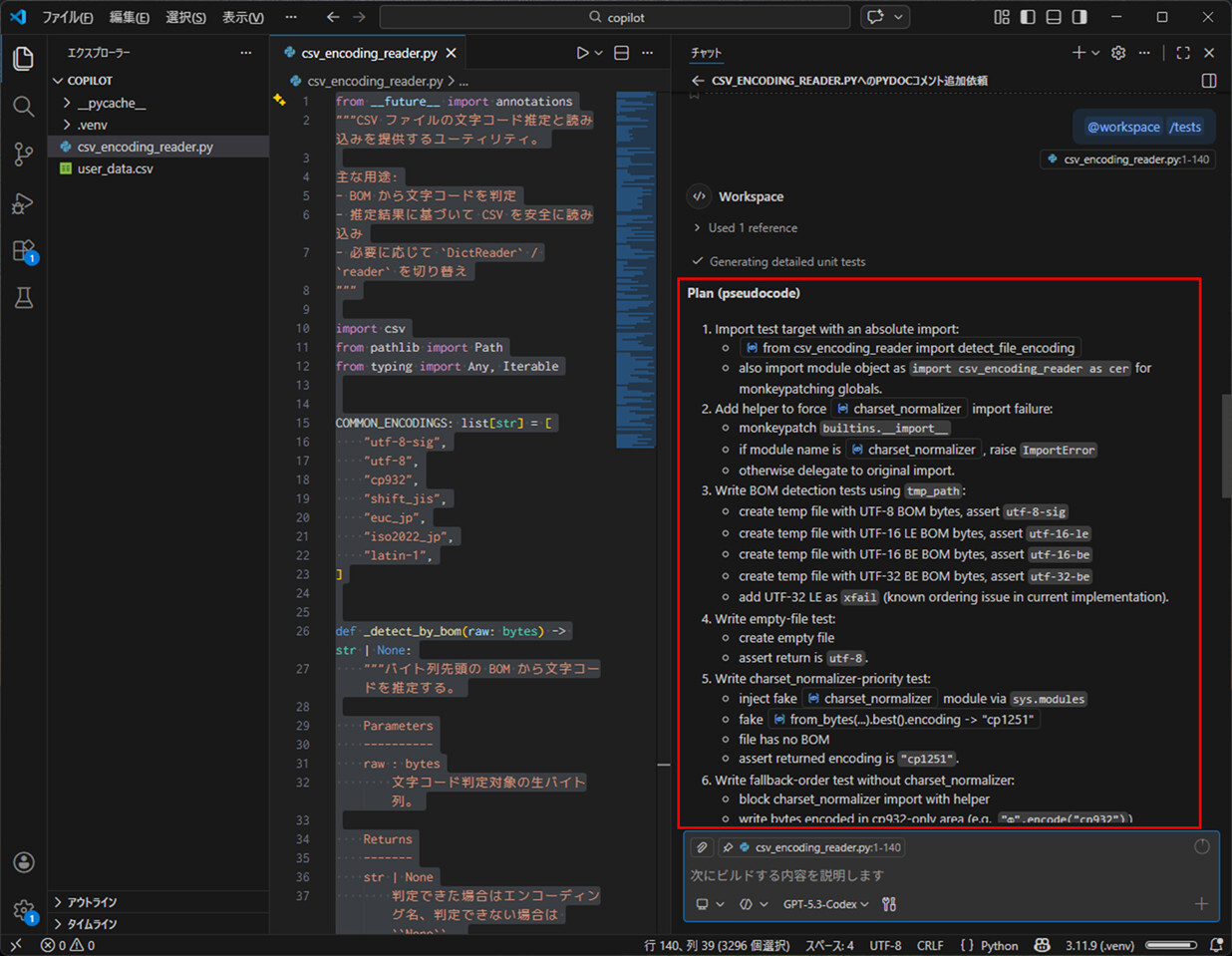
5) 以下のように、テストケースの説明文と、テストコードが表示されることが確認できる。
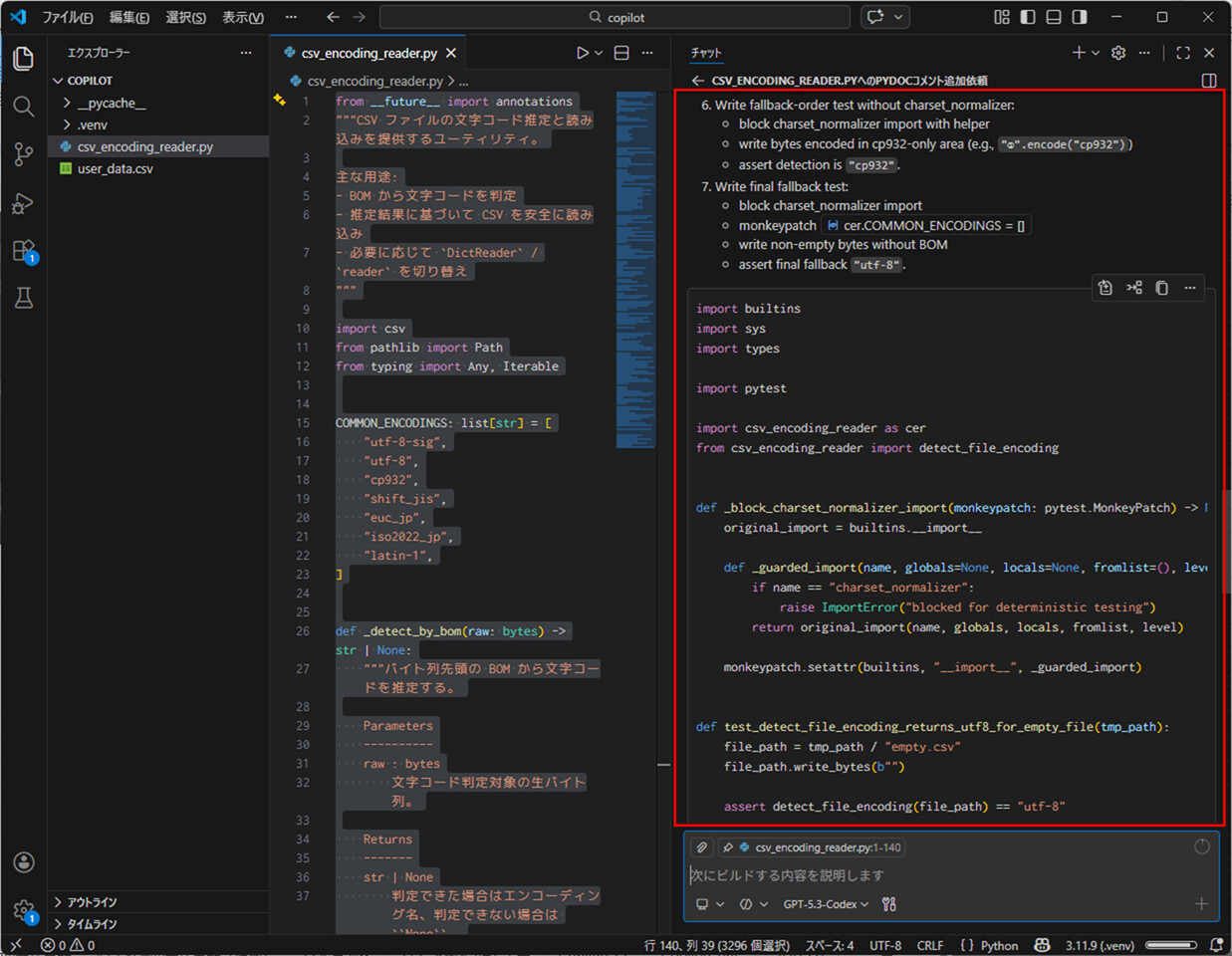
6) コード上部のコピーボタンで、テストコードのコピーが行える。
コピーしたテストコード(test_csv_encoding_reader.py)の内容は、以下の通り。
import builtins
import sys
import types
import pytest
import csv_encoding_reader as cer
from csv_encoding_reader import detect_file_encoding
def _block_charset_normalizer_import(monkeypatch: pytest.MonkeyPatch) -> None:
original_import = builtins.__import__
def _guarded_import(name, globals=None, locals=None, fromlist=(), level=0):
if name == "charset_normalizer":
raise ImportError("blocked for deterministic testing")
return original_import(name, globals, locals, fromlist, level)
monkeypatch.setattr(builtins, "__import__", _guarded_import)
def test_detect_file_encoding_returns_utf8_for_empty_file(tmp_path):
file_path = tmp_path / "empty.csv"
file_path.write_bytes(b"")
assert detect_file_encoding(file_path) == "utf-8"
def test_detect_file_encoding_detects_utf8_sig_bom(tmp_path):
file_path = tmp_path / "utf8sig.csv"
file_path.write_bytes(b"\xef\xbb\xbfcol1,col2\n1,2\n")
assert detect_file_encoding(file_path) == "utf-8-sig"
def test_detect_file_encoding_detects_utf16_le_bom(tmp_path):
file_path = tmp_path / "utf16le.csv"
file_path.write_bytes(b"\xff\xfec\x00o\x00l\x001\x00,\x00x\x00\n\x00")
assert detect_file_encoding(file_path) == "utf-16-le"
def test_detect_file_encoding_detects_utf16_be_bom(tmp_path):
file_path = tmp_path / "utf16be.csv"
file_path.write_bytes(b"\xfe\xff\x00c\x00o\x00l\x001\x00,\x00x\x00\n")
assert detect_file_encoding(file_path) == "utf-16-be"
def test_detect_file_encoding_detects_utf32_be_bom(tmp_path):
file_path = tmp_path / "utf32be.csv"
payload = "a,b\n1,2\n".encode("utf-32-be")
file_path.write_bytes(b"\x00\x00\xfe\xff" + payload)
assert detect_file_encoding(file_path) == "utf-32-be"
@pytest.mark.xfail(reason="Current BOM check order matches UTF-16-LE before UTF-32-LE.")
def test_detect_file_encoding_detects_utf32_le_bom(tmp_path):
file_path = tmp_path / "utf32le.csv"
payload = "a,b\n1,2\n".encode("utf-32-le")
file_path.write_bytes(b"\xff\xfe\x00\x00" + payload)
assert detect_file_encoding(file_path) == "utf-32-le"
def test_detect_file_encoding_uses_charset_normalizer_when_available(tmp_path, monkeypatch):
file_path = tmp_path / "normalizer.csv"
file_path.write_bytes(b"plain,ascii\n1,2\n") # no BOM
class _Best:
encoding = "cp1251"
class _Matches:
def best(self):
return _Best()
fake_module = types.SimpleNamespace(from_bytes=lambda raw: _Matches())
monkeypatch.setitem(sys.modules, "charset_normalizer", fake_module)
assert detect_file_encoding(file_path) == "cp1251"
def test_detect_file_encoding_falls_back_to_common_encodings_without_charset_normalizer(
tmp_path, monkeypatch
):
_block_charset_normalizer_import(monkeypatch)
file_path = tmp_path / "cp932.csv"
# "①" is commonly cp932-decodable and often not decodable with strict shift_jis.
file_path.write_bytes("①,2\n".encode("cp932"))
assert detect_file_encoding(file_path) == "cp932"
def test_detect_file_encoding_returns_utf8_when_no_candidates_and_no_normalizer(
tmp_path, monkeypatch
):
_block_charset_normalizer_import(monkeypatch)
monkeypatch.setattr(cer, "COMMON_ENCODINGS", [])
file_path = tmp_path / "fallback.csv"
file_path.write_bytes(b"\x80\x81\x82") # non-empty, no BOM
assert detect_file_encoding(file_path) == "utf-8"
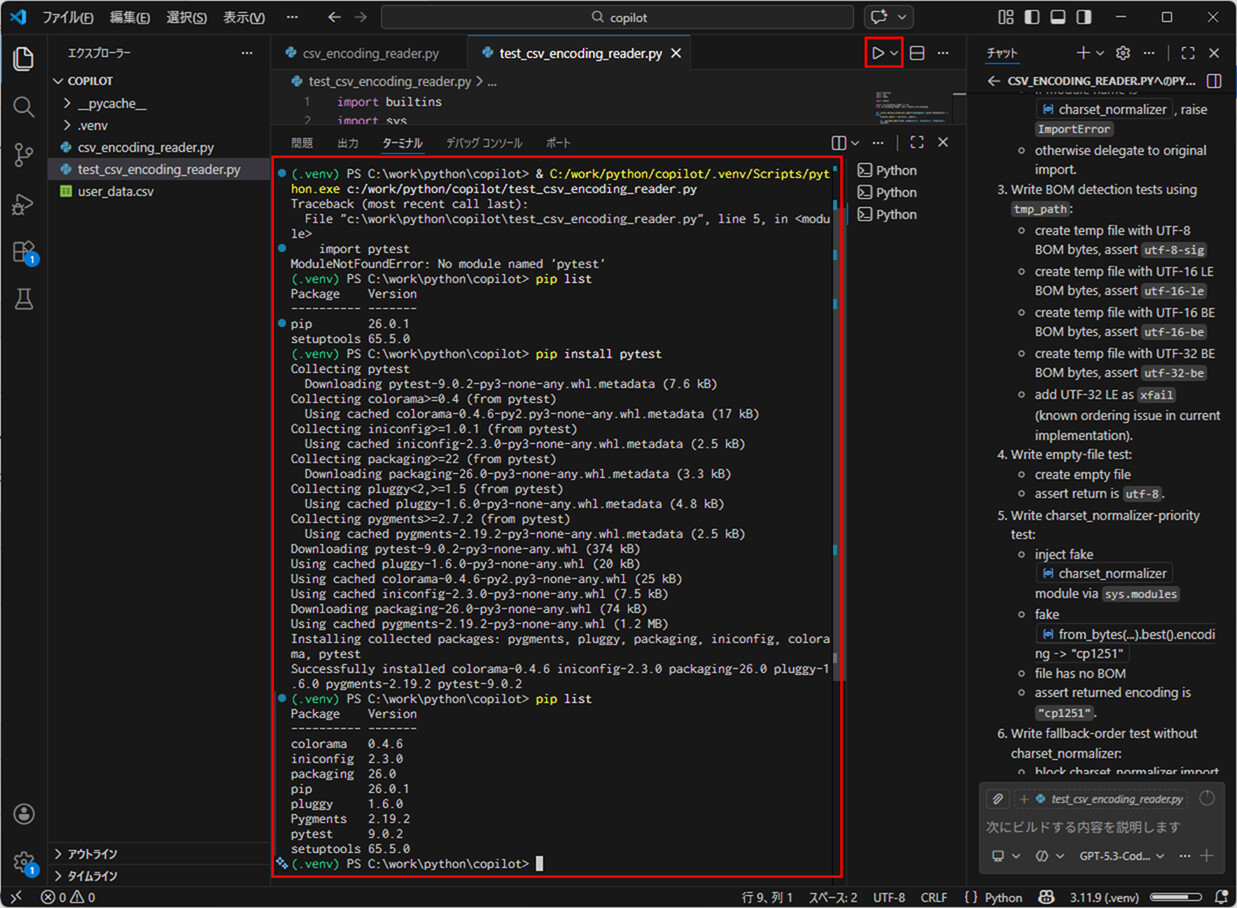
7) 画面中央の実行ボタンを押下すると、選択したソースコードが実行され、結果がターミナルに表示される。ここで、GitHub Copilotが作成してくれた仮想環境(.venv)にpytestが入っていないことが分かったため、インストールする。
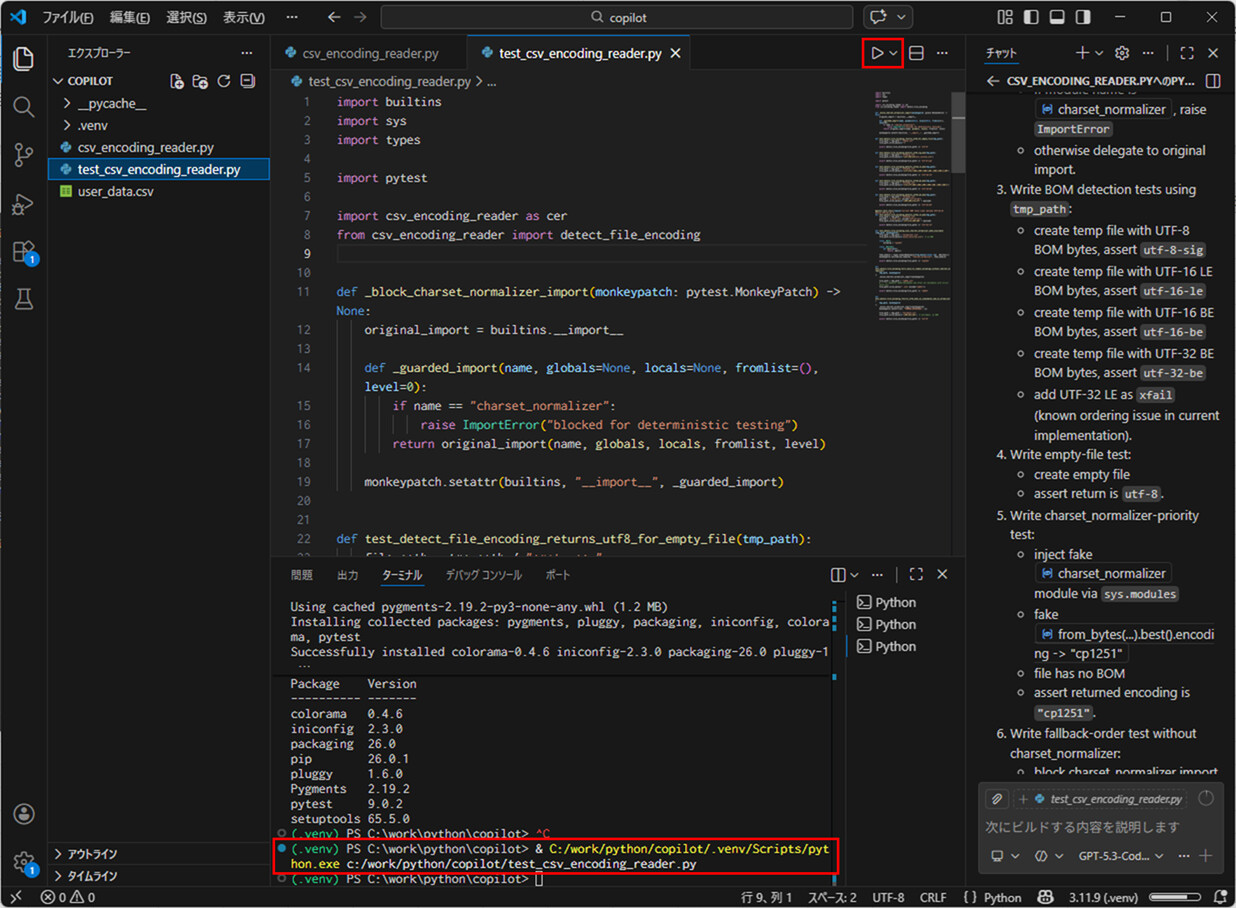
8) 実行ボタンを押下すると、テストコードが正常に実行できたのが確認できる。
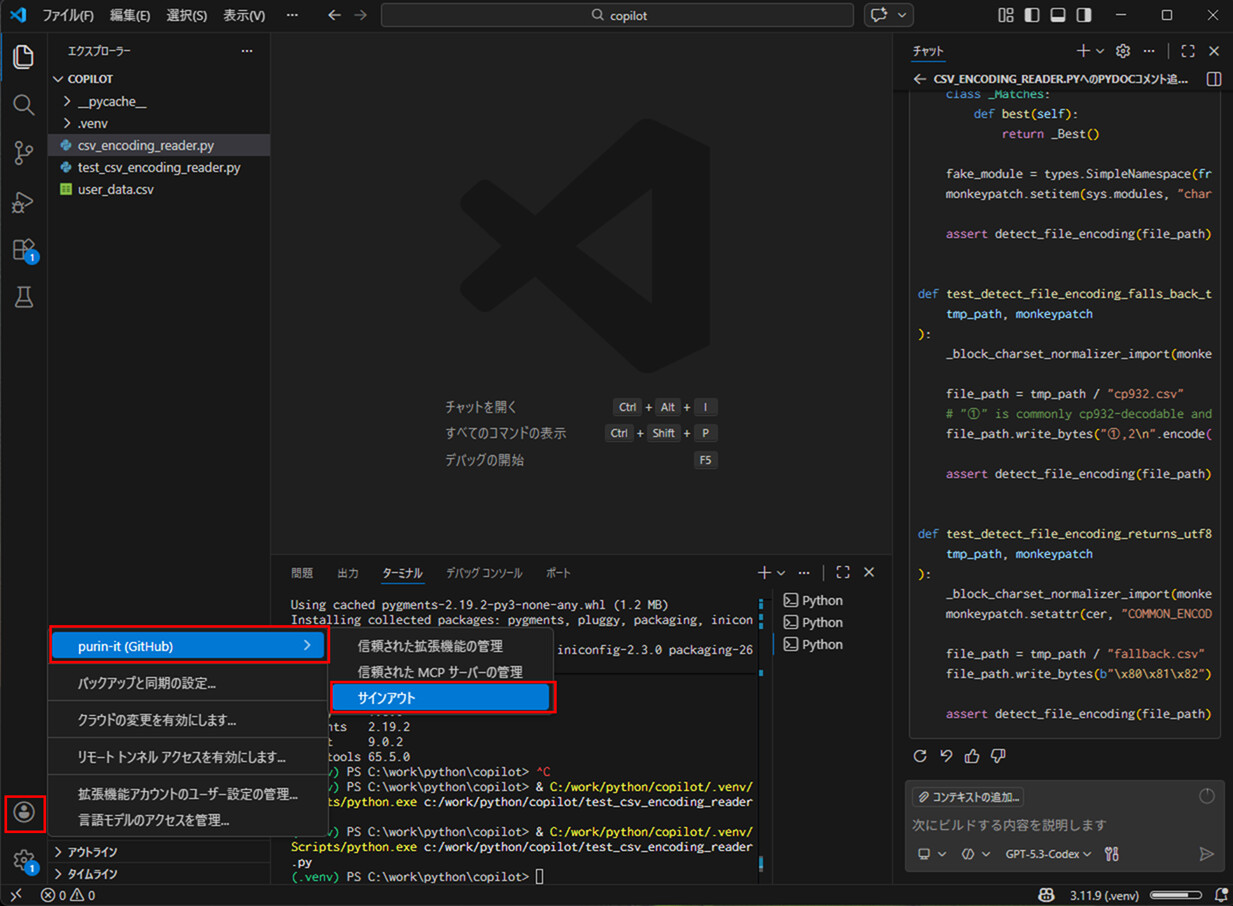
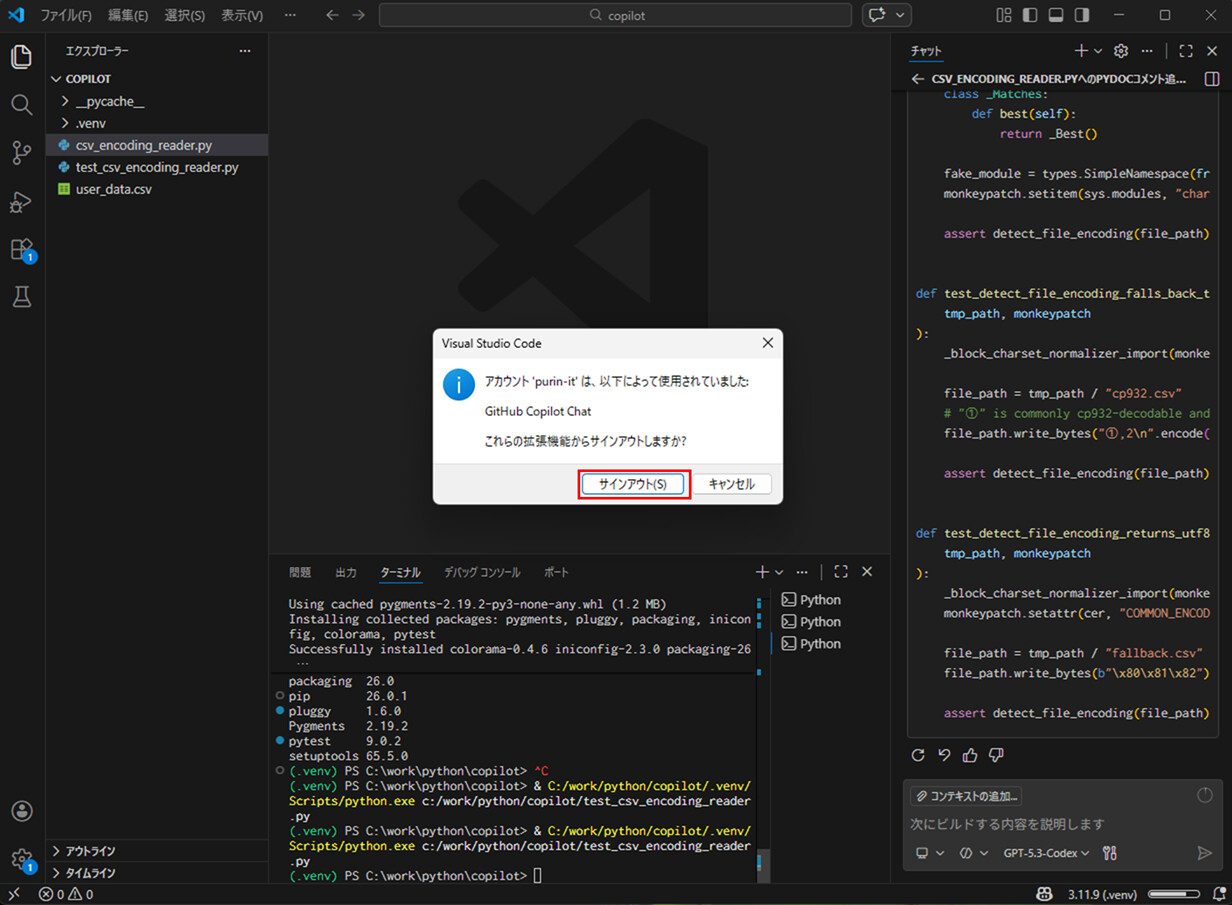
9) GitHub Copilot Chatからサインアウトするには、アカウントメニューから「サインアウト」を選択する。
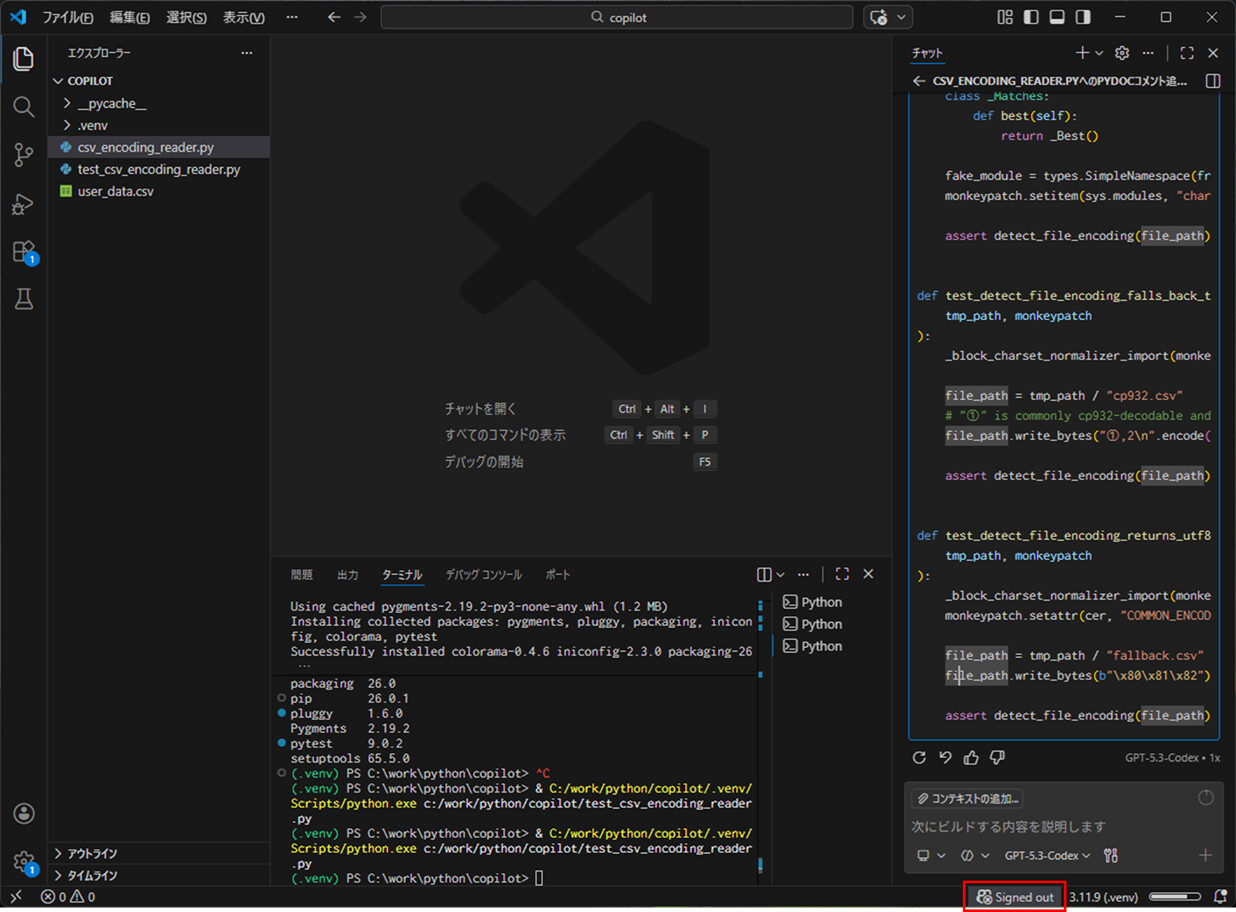
10) サインアウトが完了すると、右下のボタンが「Signed out」になっていることが確認できる。
要点まとめ
- GitHub Copilotは、OpenAIの技術を活用したAIコード補完・支援ツールで、開発エディタ(IDE)内で、ソースコードやテストコードの作成やpydocコメントの追加、コード説明文の表示等を行える。





