Pandasを利用してCSVファイルを読み込み欠損値補充をしてみた
Pythonでデータの取り込みや加工・集計、分析処理に利用できるライブラリの一つにPandasがあり、これを利用するとCSVファイルの読み込みや加工が簡単に行える。
今回は、Pandasを利用してCSVファイルの読み込み・データ抽出・欠損値の補完を行ってみたので、そのサンプルプログラムを共有する。
前提条件
今回サンプルプログラムで利用するCSVファイルは、以下の内容とする。
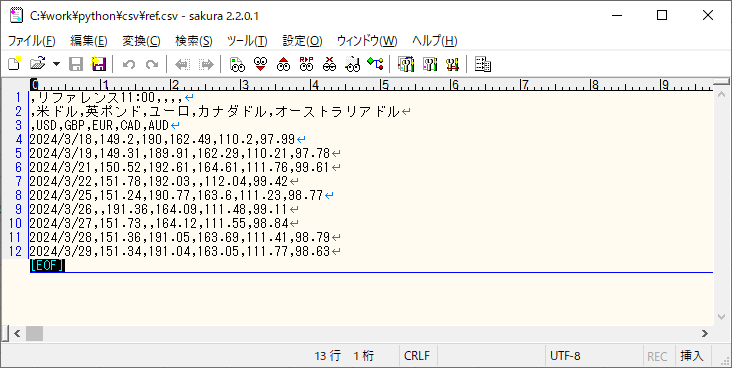
このCSVファイルは、以下の「みずほ リファレンスデータ」から一部抜粋したデータとなる。
https://www.mizuhobank.co.jp/market/historical/index.html
また、下記記事のAnacondaをインストールしJupyter Notebookを利用できること。

やってみたこと
Jupyter NotebookへのCSVファイルアップロード
Jupyter Notebook上で、Pythonのソースコード上からCSVファイルを読み込めるよう、CSVファイルをアップロードする。その手順は、以下の通り。
1) CSVファイルを読み込むため、Jupyter Notebook上で「Upload」ボタンを押下する。
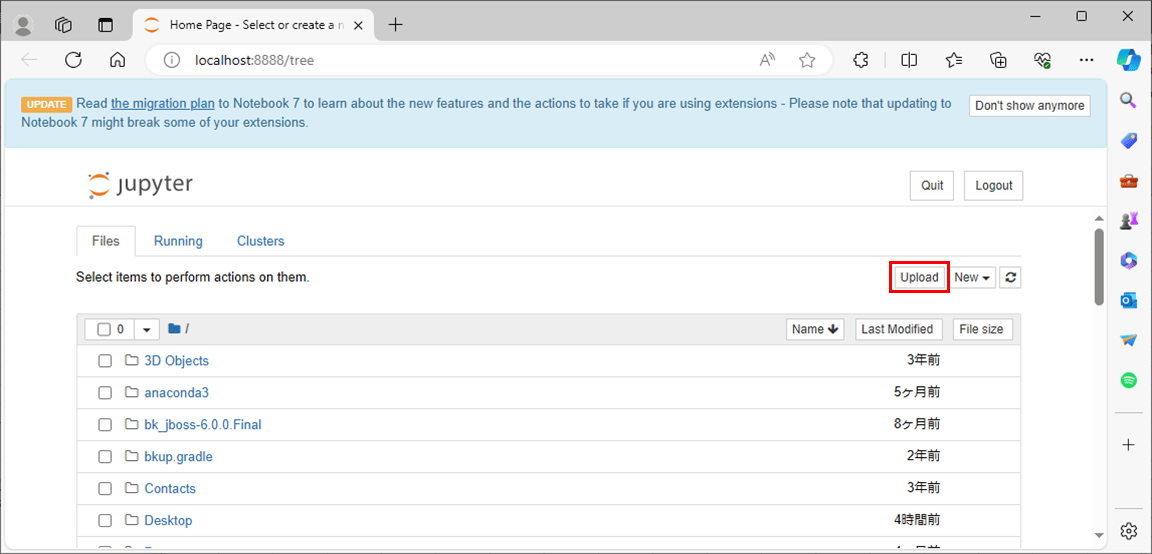
2) 読み込むCSVファイルを選択し、「開く」ボタンを押下する。
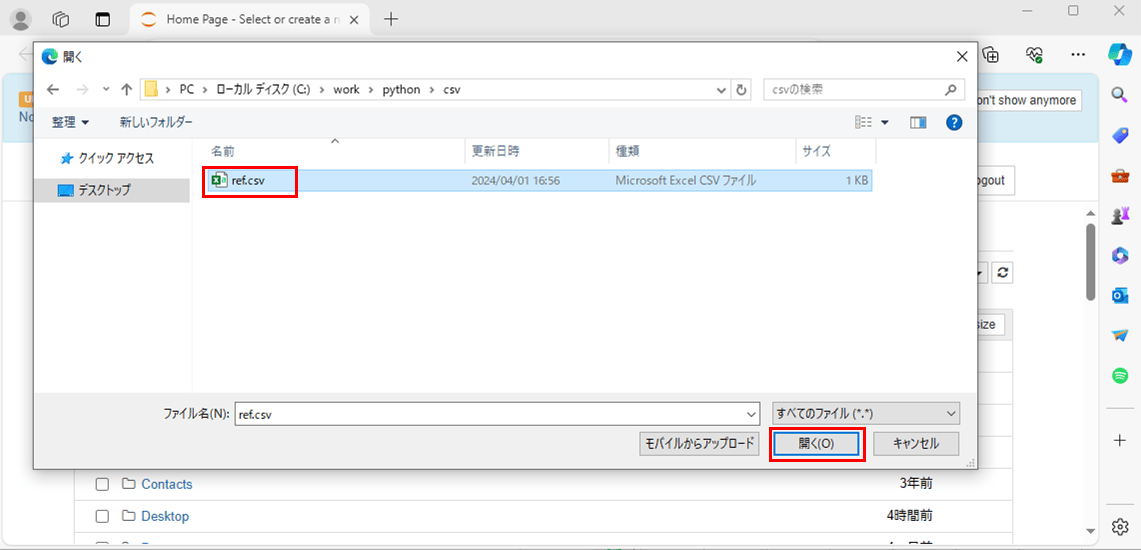
3) ファイル名はそのままで、「Upload」ボタンを押下する。
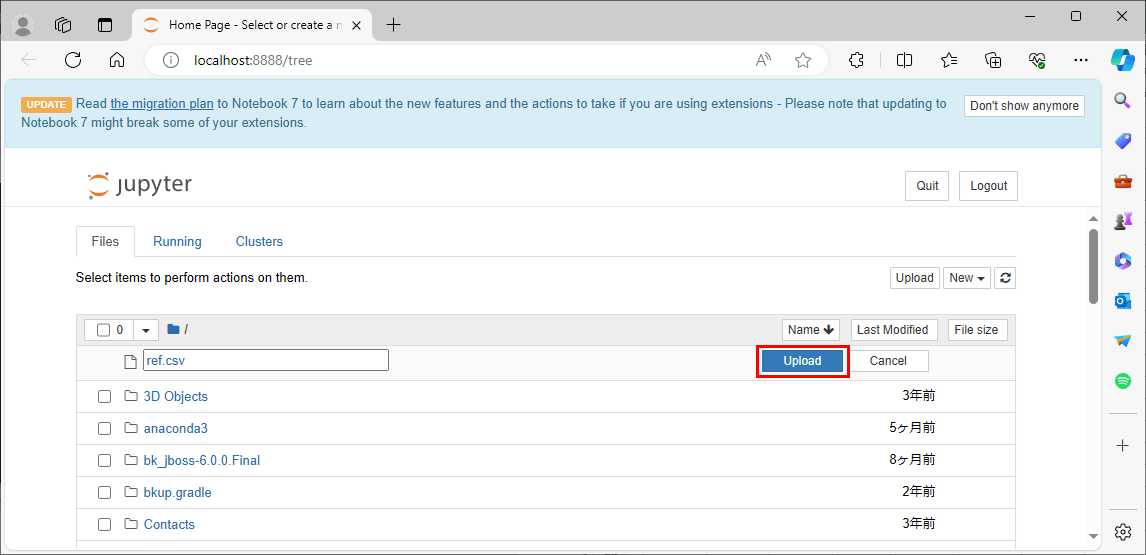
4) CSVファイルのアップロードが完了し、一覧に、アップロードしたファイルが表示されることが確認できる。

CSVファイルの読み込みとデータ抽出
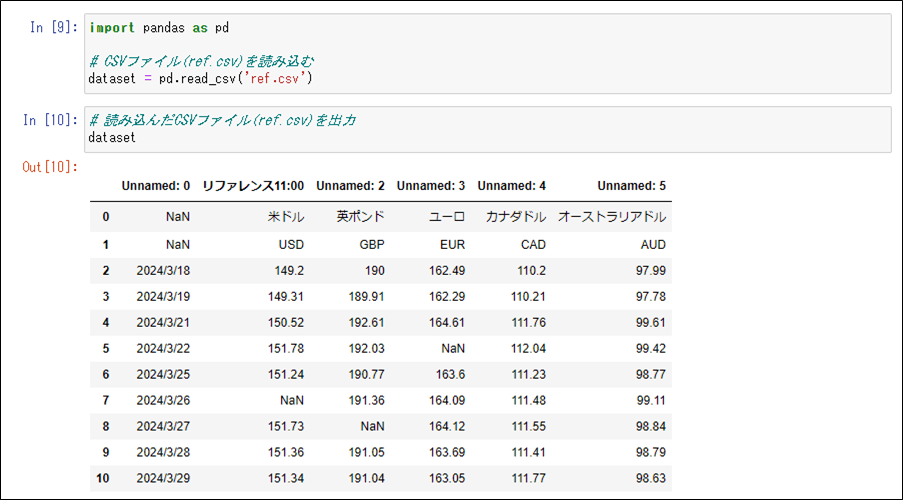
CSVファイルの読み込みには、(データ解析を行うための)Pandasのread_csvメソッドを利用する。そのサンプルプログラムと実行結果は、以下の通り。
import pandas as pd
# CSVファイル(ref.csv)を読み込む
dataset = pd.read_csv('ref.csv')# 読み込んだCSVファイル(ref.csv)を出力 dataset
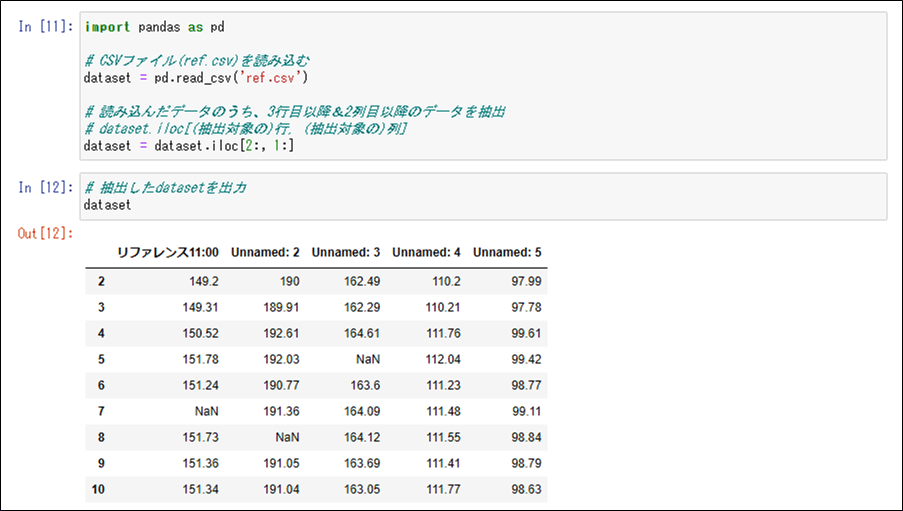
また、CSVファイルからデータ抽出するには、pandas.DataFrameのilocメソッドを利用する。そのサンプルプログラムと実行結果は、以下の通り。
import pandas as pd
# CSVファイル(ref.csv)を読み込む
dataset = pd.read_csv('ref.csv')
# 読み込んだデータのうち、3行目以降&2列目以降のデータを抽出
# dataset.iloc[(抽出対象の)行, (抽出対象の)列]
dataset = dataset.iloc[2:, 1:]# 抽出したdatasetを出力 dataset
さらに、pandas.DataFrame.valuesで、抽出したデータをNumPy配列を取得できる。そのサンプルプログラムと実行結果は、以下の通り。
import pandas as pd
# CSVファイル(ref.csv)を読み込む
dataset = pd.read_csv('ref.csv')
# 読み込んだデータのうち、3行目以降&2列目以降のデータを抽出
# dataset.iloc[(抽出対象の)行, (抽出対象の)列]
dataset = dataset.iloc[2:, 1:]
# 読み込んだデータをNumPy配列に変換し出力
dataset_ndarray = dataset.values
print(dataset_ndarray)
print()
print(type(dataset_ndarray))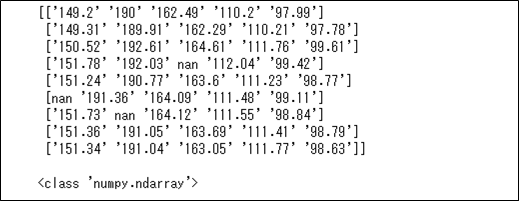

欠損値の補完
読み込んだCSVファイルの結果を確認すると、いくつか欠損値(nan)となっているが、ここを一定の規則で補完することができる。
今回は、scikit-learnのSimpleImputerクラスを利用して、欠損値に各列の平均値を補完してみたので、そのサンプルプログラムを共有する。
import pandas as pd
import numpy as np
from sklearn.impute import SimpleImputer
# csvファイル(ref.csv)を読み込む
dataset = pd.read_csv('ref.csv')
# 読み込んだデータのうち、3行目以降&2列目以降のデータを抽出し、
# NumPy配列に変換後、その結果を出力
dataset_ndarray = dataset.iloc[2:, 1:].values
print(dataset_ndarray)
print()
# 左端から2列目の欠損値(nan)に、各列の平均値を補完する
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer.fit(dataset_ndarray[:, :3])
dataset_ndarray[:, :3] = imputer.transform(dataset_ndarray[:, :3])
print(dataset_ndarray)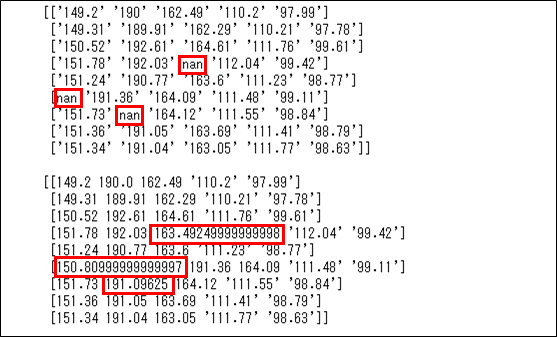
なお、欠損値を補完する方法は、平均値以外にも、中央値・最頻値等を利用できる。その指定方法は、以下のサイトを参照のこと。
https://qiita.com/k-ysd/items/ee990bcf4f19301335ba
実際に、1~3列目各列の(nan以外の)平均値を算出した結果は以下の通りで、実際に補完された平均値と一致していることが確認できる。
import pandas as pd
import numpy as np
# csvファイル(ref.csv)を読み込む
dataset = pd.read_csv('ref.csv')
# 読み込んだデータのうち、3行目以降&2列目以降のデータを抽出し、
# NumPy配列に変換
dataset_ndarray = dataset.iloc[2:, 1:].values
# 1列目の値を抽出しfloat型に変換後、nan以外の平均値を算出
input_data_1 = dataset_ndarray[:, 0].astype(float)
print("*** 1列目の値の平均 ***")
print(input_data_1)
print(np.nanmean(input_data_1))
print()
# 2列目の値を抽出しfloat型に変換後、nan以外の平均値を算出
input_data_2 = dataset_ndarray[:, 1].astype(float)
print("*** 2列目の値の平均 ***")
print(input_data_2)
print(np.nanmean(input_data_2))
print()
# 3列目の値を抽出しfloat型に変換後、nan以外の平均値を算出
input_data_3 = dataset_ndarray[:, 2].astype(float)
print("*** 3列目の値の平均 ***")
print(input_data_3)
print(np.nanmean(input_data_3))
要点まとめ
- Pythonでデータの取り込みや加工・集計、分析処理に利用できるライブラリの一つにPandasがあり、これを利用するとCSVファイルの読み込みや加工が簡単に行える。





