PythonでCSVファイルのデータをSQL Serverの一時テーブルに格納するSQLを作成してみた
特定のデータを検索条件に利用してデータ抽出を行う時などに、CSVファイルのデータを一時テーブルに格納したい場合がある。
今回は、PythonでCSVファイルのデータをSQL Serverの一時テーブルに格納するSQLを作成してみたので、そのサンプルプログラムを共有する。
前提条件
以下のPycharmのインストールが完了していること。

また、以下の記事のPythonのインストールが完了していること。

サンプルプログラムの作成
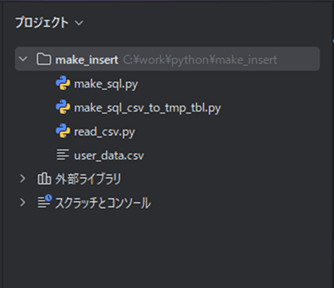
作成したサンプルプログラムの構成は、以下の通り。
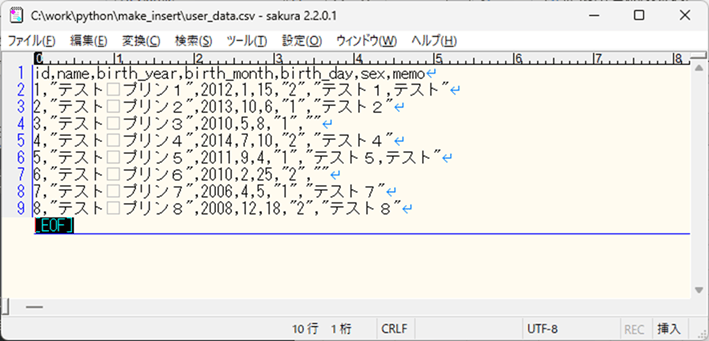
取り込むCSVファイルであるuser_data.csvは、以下の通り。
また、CSVファイルのデータを取り込む処理(read_csv.py)は、以下の通り。
import csv
from chardet import detect
# CSVファイルのデータを読み込むクラス
class ReadCsv:
# 引数にCSVファイルを渡してインスタンスを生成
def __init__(self, input_csv_file):
self.input_csv_file = input_csv_file
# CSVファイルの文字コードを判定
# 判定した文字コードがSHIFT_JISの場合は、CP932に変換する
def get_csv_encoding(self):
f = open(self.input_csv_file, 'rb')
rawdata = f.read()
f.close()
encoding = detect(rawdata)['encoding']
if "SHIFT_JIS" == encoding:
encoding = "CP932"
return encoding
# CSVファイルのヘッダー行を取得
def get_csv_header(self):
encoding = self.get_csv_encoding()
f = open(self.input_csv_file, 'r', encoding=encoding)
csv_reader = csv.reader(f)
header = next(csv_reader) # ヘッダー行(1行目)を取得
f.close()
return header
# CSVファイルのデータ行を取得
def get_csv_data(self):
encoding = self.get_csv_encoding()
f = open(self.input_csv_file, 'r', encoding=encoding)
csv_reader = csv.reader(f)
data_list = []
for row in csv_reader:
data_list.append(row)
f.close()
del data_list[0] # ヘッダー行(1行目)を削除
return data_list
さらに、CSVファイルのデータを一時テーブルに格納するSQLを作成する処理(make_sql.py)は、以下の通り。
from read_csv import ReadCsv
# CSVファイルのデータを一時テーブルに格納するSQLを作成
class MakeTmpTblSql:
# 引数にCSVファイル(入力)・SQLファイル(出力)を渡してインスタンスを生成
def __init__(self, input_csv_file, output_sql_file):
self.input_csv_file = input_csv_file
self.output_sql_file = output_sql_file
# 出力ファイルの文字コードはUTF-8、一時テーブル名はtmpTbl、
# 一時テーブルの各カラムはNVARCHAR(255)固定とする
self.output_encoding = "UTF-8"
self.tmp_tbl_name = "#tmpTbl"
self.col_type = "NVARCHAR"
self.col_length = 255
# insert文の処理単位(最大1000)を指定する
self.chunk_size = 3
# 一時テーブルを作成するSQL文を出力
def make_sql_create_tmp_tbl(self):
read_csv = ReadCsv(self.input_csv_file)
header = read_csv.get_csv_header()
output_sql = "CREATE TABLE " + self.tmp_tbl_name + " ( \n"
for col_name in header:
output_sql += (" " + col_name + " " + self.col_type
+ " (" + str(self.col_length) + "), \n")
output_sql = output_sql[:-3]
output_sql += "\n"
output_sql += "); \n"
fw = open(self.output_sql_file, 'w', encoding=self.output_encoding)
fw.write(output_sql)
fw.write('\n')
fw.close()
# 一時テーブルにデータを追加するSQL文を出力
def make_sql_insert_tmp_tbl(self):
read_csv = ReadCsv(self.input_csv_file)
data_list = read_csv.get_csv_data()
output_sql = ""
for idx, data in enumerate(data_list):
if idx % self.chunk_size == 0:
output_sql += "INSERT INTO " + self.tmp_tbl_name + " VALUES \n"
output_sql += " ("
for col_data in data:
output_sql += "N'" + col_data + "', "
output_sql = output_sql[:-2]
output_sql += "), \n"
if (idx % self.chunk_size == (self.chunk_size - 1)
or idx == len(data_list) - 1):
output_sql = output_sql[:-3]
output_sql += "; \n\n"
fw = open(self.output_sql_file, 'a', encoding=self.output_encoding)
fw.write(output_sql)
fw.close()
# 一時テーブルのデータを全て取得するSQL文を出力
def make_sql_select_tmp_tbl(self):
output_sql = "SELECT * FROM " + self.tmp_tbl_name + ";"
fw = open(self.output_sql_file, 'a', encoding=self.output_encoding)
fw.write(output_sql)
fw.write("\n\n")
fw.close()
# 一時テーブルを削除するSQL文を出力
def make_sql_drop_tmp_tbl(self):
output_sql = "DROP TABLE " + self.tmp_tbl_name + ";"
fw = open(self.output_sql_file, 'a', encoding=self.output_encoding)
fw.write(output_sql)
fw.write("\n")
fw.close()
また、CSVファイルのデータを一時テーブルに格納するSQLを作成する処理を呼び出すプログラム(make_sql_csv_to_tmp_tbl.py)は、以下の通り。
from make_sql import MakeTmpTblSql
# CSVファイルのデータを一時テーブルに格納するSQLを作成する処理の呼び出し
if __name__ == "__main__":
make_sql = MakeTmpTblSql('user_data.csv', 'make_user_data_tmp.sql')
make_sql.make_sql_create_tmp_tbl()
make_sql.make_sql_insert_tmp_tbl()
make_sql.make_sql_select_tmp_tbl()
make_sql.make_sql_drop_tmp_tbl()上記ソースコード内容は、以下のサイトも参照のこと。
https://github.com/purin-it/python/tree/master/python-csv-to-sql-server-tmp-tbl/

サンプルプログラムの実行結果
サンプルプログラムを実行し、生成されたSQLファイルの実行結果は、以下の通り。
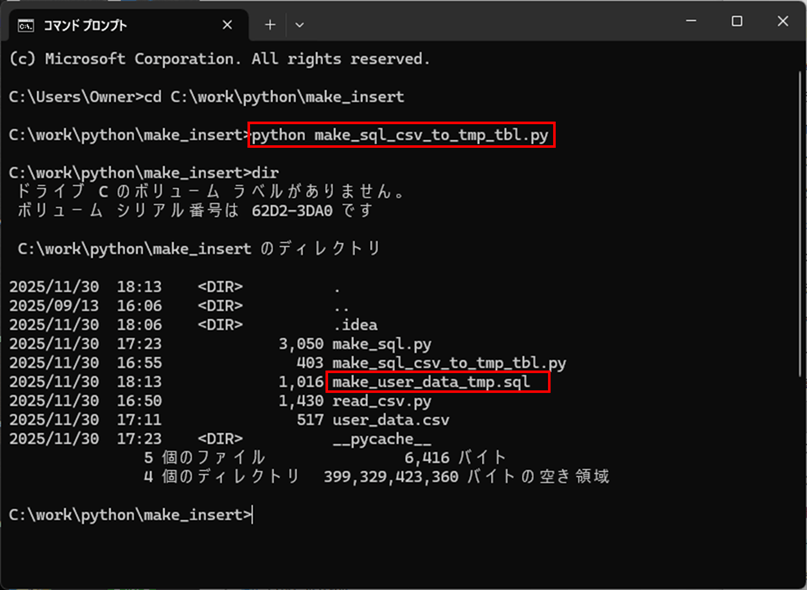
1)「python make_sql_csv_to_tmp_tbl.py」を実行すると、以下のように、SQLファイル(make_user_data_tmp.sql)が作成されることが確認できる。
2) 生成された「make_user_data_tmp.sql」の内容は、以下の通り。
CREATE TABLE #tmpTbl ( id NVARCHAR (255), name NVARCHAR (255), birth_year NVARCHAR (255), birth_month NVARCHAR (255), birth_day NVARCHAR (255), sex NVARCHAR (255), memo NVARCHAR (255) ); INSERT INTO #tmpTbl VALUES (N'1', N'テスト プリン1', N'2012', N'1', N'15', N'2', N'テスト1,テスト'), (N'2', N'テスト プリン2', N'2013', N'10', N'6', N'1', N'テスト2'), (N'3', N'テスト プリン3', N'2010', N'5', N'8', N'1', N''); INSERT INTO #tmpTbl VALUES (N'4', N'テスト プリン4', N'2014', N'7', N'10', N'2', N'テスト4'), (N'5', N'テスト プリン5', N'2011', N'9', N'4', N'1', N'テスト5,テスト'), (N'6', N'テスト プリン6', N'2010', N'2', N'25', N'2', N''); INSERT INTO #tmpTbl VALUES (N'7', N'テスト プリン7', N'2006', N'4', N'5', N'1', N'テスト7'), (N'8', N'テスト プリン8', N'2008', N'12', N'18', N'2', N'テスト8'); SELECT * FROM #tmpTbl; DROP TABLE #tmpTbl;
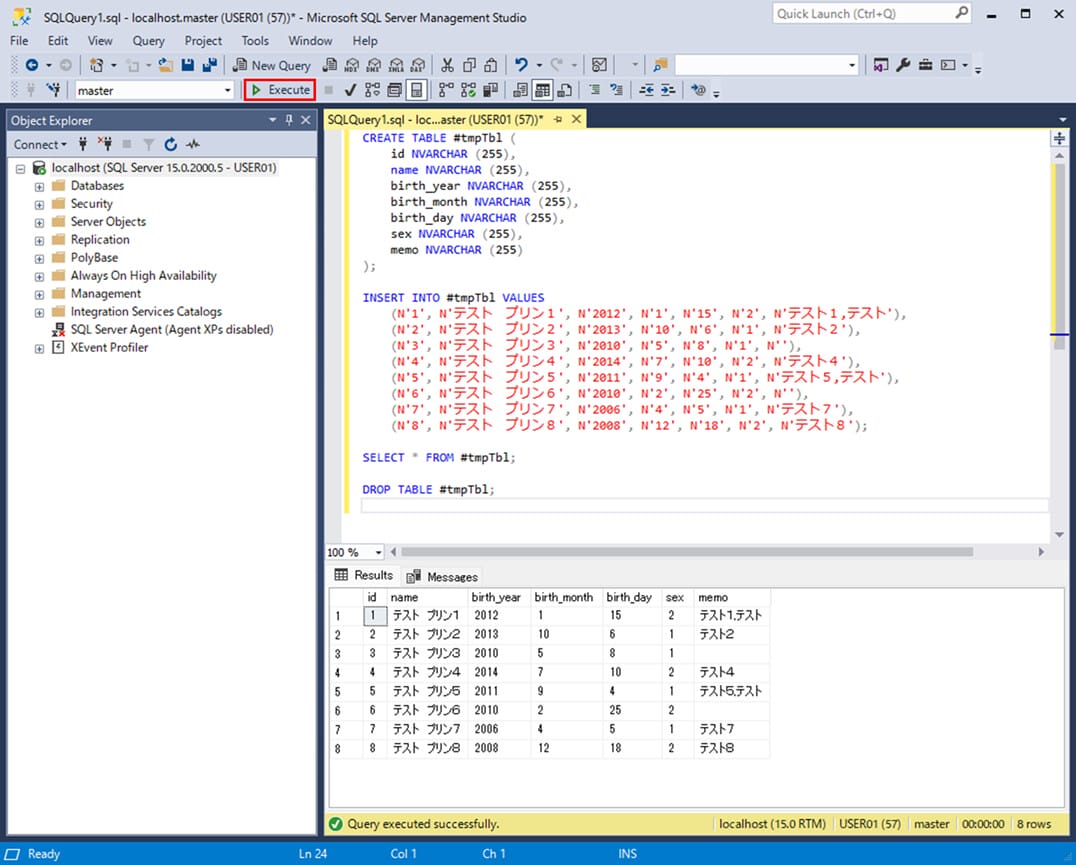
3)「make_user_data_tmp.sql」をSSMSで実行した結果は以下の通りで、CSVファイル(user_data.csv)の中身が、一時テーブル(#tmpTbl)に格納されることが確認できる。

4)「make_sql.py」のself.chunk_size=1000に変更した場合に、生成されたSQLファイル(make_user_data_tmp.sql)の内容は以下の通りで、一時テーブルへのINSERT文が1本にまとめられることが確認できる。
CREATE TABLE #tmpTbl ( id NVARCHAR (255), name NVARCHAR (255), birth_year NVARCHAR (255), birth_month NVARCHAR (255), birth_day NVARCHAR (255), sex NVARCHAR (255), memo NVARCHAR (255) ); INSERT INTO #tmpTbl VALUES (N'1', N'テスト プリン1', N'2012', N'1', N'15', N'2', N'テスト1,テスト'), (N'2', N'テスト プリン2', N'2013', N'10', N'6', N'1', N'テスト2'), (N'3', N'テスト プリン3', N'2010', N'5', N'8', N'1', N''), (N'4', N'テスト プリン4', N'2014', N'7', N'10', N'2', N'テスト4'), (N'5', N'テスト プリン5', N'2011', N'9', N'4', N'1', N'テスト5,テスト'), (N'6', N'テスト プリン6', N'2010', N'2', N'25', N'2', N''), (N'7', N'テスト プリン7', N'2006', N'4', N'5', N'1', N'テスト7'), (N'8', N'テスト プリン8', N'2008', N'12', N'18', N'2', N'テスト8'); SELECT * FROM #tmpTbl; DROP TABLE #tmpTbl;
5) 4)の実行結果は以下の通りで、3)と同様、CSVファイル(user_data.csv)の中身が、一時テーブル(#tmpTbl)に格納されることが確認できる。
要点まとめ
- 特定のデータを検索条件に利用してデータ抽出を行う時などに、CSVファイルのデータを一時テーブルに格納したい場合があるが、そのような処理は、Pythonプログラムで作成できる。





