Pandasを利用してOracle DBのデータを取得してみた
Pythonでデータの取り込みや加工・集計、分析処理に利用できるライブラリの一つにPandasがあり、これを利用するとCSVファイルの読み込みに加え、データベースのデータの読み込みも行える。
今回は、Pandasを利用してOracle DBのデータ読み込みを行ってみたので、その手順とサンプルプログラムを共有する。
前提条件
下記記事の、A5M2を利用したOracle DBへの接続が行えること。

Oracle DBへ接続する際の接続設定は以下の通りで、パスワードは「USER01」であること。
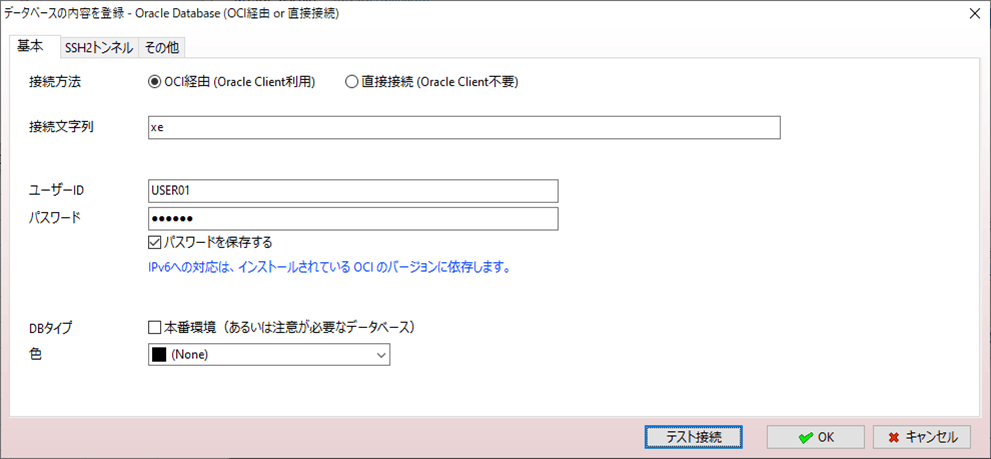
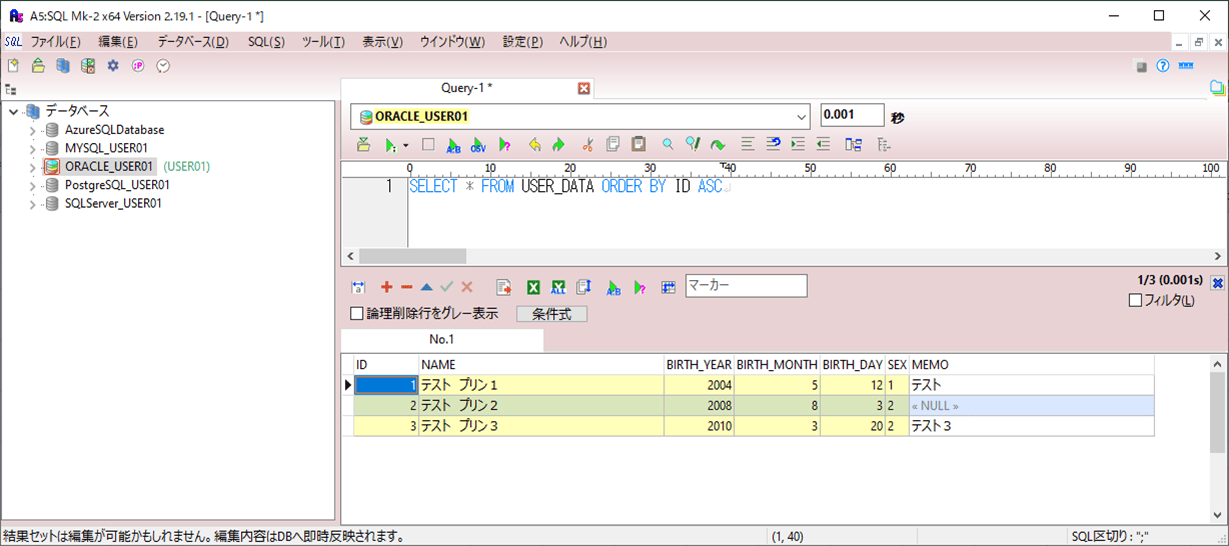
また、USER_DATAテーブルに、以下のデータが作成されていること。
さらに、下記記事のAnacondaをインストールしJupyter Notebookを利用できること。

やってみたこと
oracledbパッケージのインストール
PythonでOracle DBに接続するには、Anacondaでoracledbパッケージを使えるようにする必要がある。その手順は、以下の通り。
1) Windowsのスタートメニューから「Anaconda Prompt」を選択する。
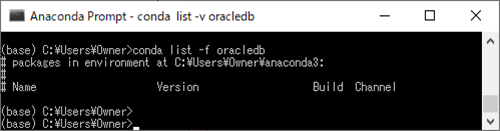
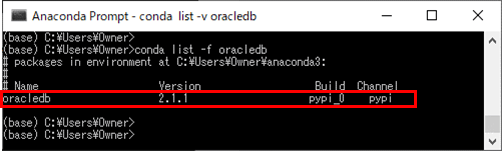
2) 以下のように、「conda list -f oracledb」コマンドを実行し、Anacondaにoracledbパッケージが含まれていないことを確認する。
3)「pip install oracledb」コマンドを実行し、oracledbパッケージをインストールする。
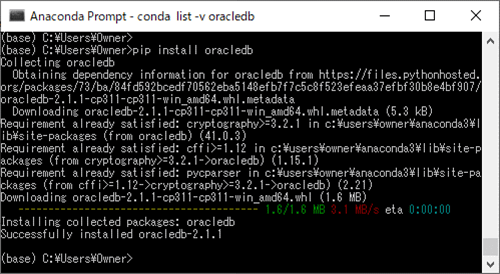
4)「conda list -f oracledb」コマンドを再度実行し、Anacondaにoracledbパッケージがインストールされたことを確認する。

oracledbによるSELECT文の実行
oracledbを利用して、Oracle DBのデータを取得し表示するサンプルプログラムと実行結果は、以下の通り。
import oracledb
# OracleDBへの接続情報
oracle_user = "USER01"
oracle_passwd = "USER01"
oracle_hostname = "localhost"
oracle_sid = "xe"
oracle_dsn = oracle_hostname + "/" + oracle_sid
# OracleDBを初期化し、接続
oracledb.init_oracle_client()
connection = oracledb.connect(user=oracle_user
, password=oracle_passwd, dsn=oracle_dsn)
# SELECT文を定義
# 複数行にまたがる文字列なので、トリプルクォートで囲う
sql_query = """ SELECT ID, NAME FROM USER_DATA
ORDER BY ID ASC """
print("*** 実行するSELECT文 ***")
print(sql_query)
print()
# SELECT文を実行し、結果を出力
cursor = connection.cursor()
cursor.execute(sql_query)
print("*** 実行結果 ***")
for id, name in cursor:
print("id =" + str(id) + ", name = " + name)
# OracleDBから切断
connection.close()
PandasによるSELECT文の実行
Pandasを利用して、Oracle DBのデータを取得する際、以下のサンプルプログラムを実行すると、実行は行えるものの、SQLAlchemyのみがサポート対象である旨の警告が出てしまう。
import oracledb
import pandas as pd
# OracleDBへの接続情報
oracle_user = "USER01"
oracle_passwd = "USER01"
oracle_hostname = "localhost"
oracle_sid = "xe"
oracle_dsn = oracle_hostname + "/" + oracle_sid
# OracleDBを初期化し、接続
oracledb.init_oracle_client()
connection = oracledb.connect(user=oracle_user
, password=oracle_passwd, dsn=oracle_dsn)
# SELECT文を定義
# 複数行にまたがる文字列なので、トリプルクォートで囲う
sql_query = """ SELECT * FROM USER_DATA
ORDER BY ID ASC """
print("*** 実行するSELECT文 ***")
print(sql_query)
# SELECT文を実行し、datasetに格納
dataset = pd.read_sql(sql_query, con=connection)
# OracleDBから切断
connection.close()
# 取得したデータを表示 dataset
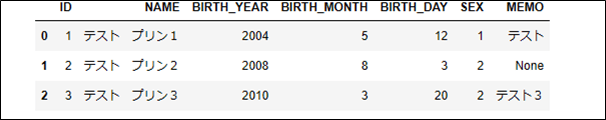
上記ソースコードを、SQLAlchemyを利用するよう修正したサンプルプログラムと実行結果は、以下の通り。
import oracledb
import pandas as pd
from sqlalchemy.engine.url import URL
from sqlalchemy.engine.create import create_engine
# OracleDBへの接続情報
oracle_user = "USER01"
oracle_passwd = "USER01"
oracle_hostname = "localhost"
oracle_sid = "xe"
# OracleDBへの接続URLを生成
oracle_url = URL.create(
drivername='oracle+cx_oracle',
username=oracle_user,
password=oracle_passwd,
host=oracle_hostname,
database=oracle_sid
)
# OracleDBを初期化
oracledb.init_oracle_client()
# SQLAlchemyを使ってOracleDBに接続する際のエンジンを定義
engine = create_engine(oracle_url)
# SELECT文を定義
# 複数行にまたがる文字列なので、トリプルクォートで囲う
sql_query = """ SELECT * FROM USER_DATA
ORDER BY ID ASC """
print("*** 実行するSELECT文 ***")
print(sql_query)
# SELECT文を実行し、dataset2に格納
dataset2 = pd.read_sql(sql_query, con=engine)
# 取得したデータを表示 dataset2
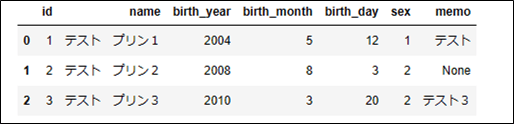
なお、上記実行結果になるには、cx-oracleパッケージのインストールする必要がある。cx-oracleパッケージをインストールしていない場合、以下のエラーメッセージが表示される。
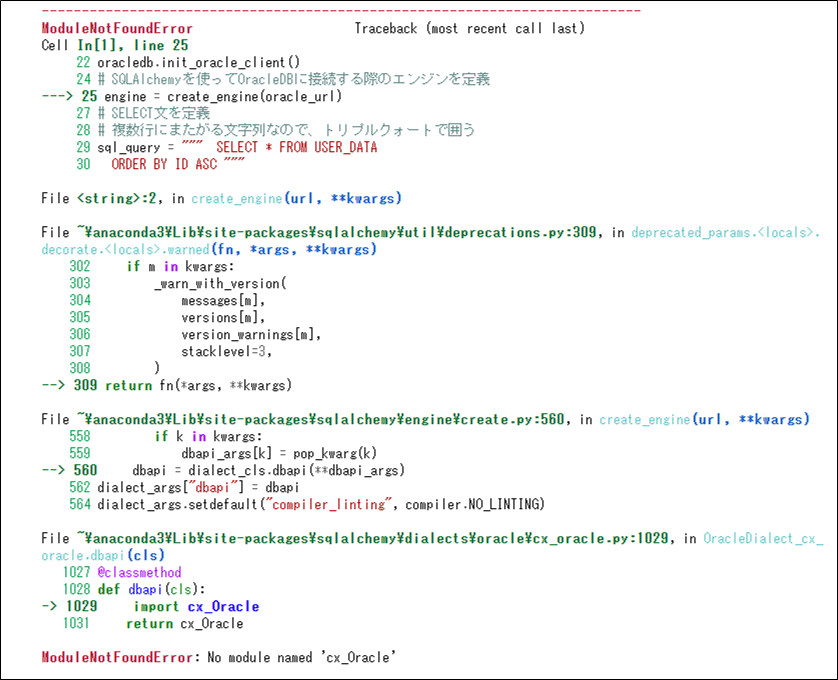

cx-oracleパッケージのインストール
SQLAlchemyを利用するには、cx-oracleパッケージのインストールが必要である。その手順は、以下の通り。
1) Anacondaプロンプトで「pip install cx_Oracle」コマンドを実行すると、Microsoft Visual C++ 14.0以降がインストールされていない場合、以下のエラーメッセージが表示される。
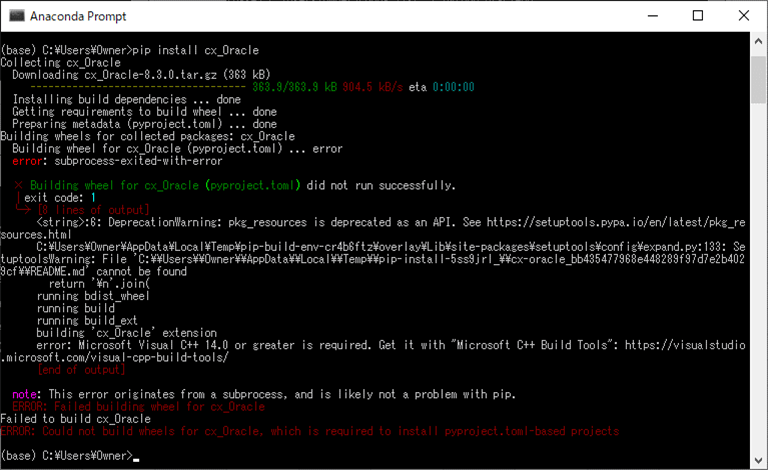
2) 以下のサイトの記載内容に従って、Microsoft Visual C++ 14.0以降をインストールする。
「microsoft-visual-c-14-0-or-greater-is-required-」が出た場合の対処方法
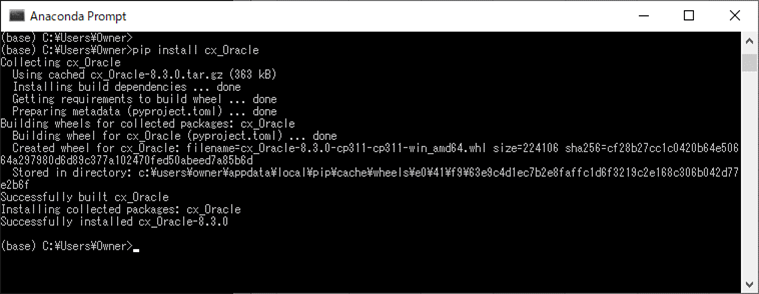
3) Anacondaプロンプトで「pip install cx_Oracle」コマンドを再度実行すると、以下のように、cx-oracleパッケージがインストールされる。
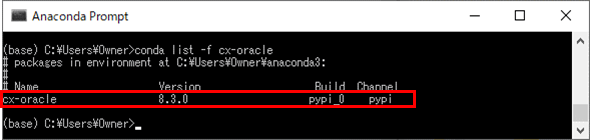
4)「conda list -f cx-oracle」コマンドを実行し、Anacondaにcx-oracleパッケージがインストールされたことを確認する。
要点まとめ
- PythonでOracle DBに接続するには、oracledbパッケージをインストールする必要がある。
- Pandasのread_sqlメソッドを利用して、Oracle DBのデータを取得すると、実行は行えるものの、SQLAlchemyのみがサポート対象である旨の警告が出てしまう。
- SQLAlchemyを利用してOracle DBに接続するには、cx-oracleパッケージをインストールする必要がある。





